Building a High Performance Container Solution with Super Computing Cluster and Singularity
Alibaba Cloud Elastic High Performance Computing (E-HPC) service provides users with one-stop HPC services over the public cloud based on the Alibaba Cloud infrastructure. E-HPC automatically integrates the IaaS-layer hardware resources to provide users with on-cloud HPC clusters. In addition, E-HPC further supports the high availability of on-cloud HPC services and provides new features, such as CloudMetrics multidimensional performance monitoring and low-cost resumable computing, to allow users to use on-cloud HPC services in a better and more cost-effective manner.
This article introduces the elastic high performance container solution launched by Alibaba Cloud Super Computing Cluster and its applications in the Molecular Dynamics (MD) and AI fields.
High Performance Container: Singularity
Singularity is a container technology developed by the Lawrence Berkeley National Lab specifically for large-scale and cross-node HPC and DL workloads. Singularity features lightweight, fast deployment, and convenient migration. It supports conversion from Docker images to Singularity images. Singularity differs from Docker in the following aspects:
User Permissions
Singularity can be started by both root and non-root users. Before and after the startup of the container, the user context remains unchanged. Therefore, user permissions are the same both inside and outside the container.
Performance and Isolation
Singularity emphasizes the convenience, portability, and scalability of the container service, and weakens the high isolation of the container process. Therefore, Singularity is more lightweight, has a smaller kernel namespace, and results in less performance loss.

The following figure shows the HPL performance data measured when different containers are used on a single Shenlong bare metal server (ecs.ebmg5.24xlarge, Intel Xeon (Skylake) Platinum 8163, 2.5 GHz, 96 vCPUs, and 384 GB). As shown in the following figure, the HPL performance measured when the Singularity container is used is slightly better than that when the Docker container is used, and is equivalent to that of the host.

HPC-Optimized
Singularity is highly suitable for scenarios where HPC is used. It allows full utilization of host software and hardware resources, including the HPC scheduler (PBS and Slurm), cross-node communication library (IntelMPI and OpenMPI), network interconnection (Ethernet and InfiniBand), file systems, and accelerators (GPU). Users can use Singularity without having to perform extra adaptation to HPC.

E-HPC Elastic High Performance Container Solution
Alibaba Cloud E-HPC integrates the open source Singularity container technology. While supporting the rapid deployment and flexible migration of user software environments, E-HPC also ensures the high availability of on-cloud HPC services and compatibility with existing E-HPC components, delivering an efficient and easy-to-use elastic and high performance container solution to users.

Users only need to pack and upload their local software environments to the Docker Hub to complete the entire process on the E-HPC console: Create a cluster > Pull an image > Deploy a container application > Submit a job > Monitor the performance and query monitoring results. In this way, users can reduce the HPC costs and improve the scientific research efficiency and production efficiency.
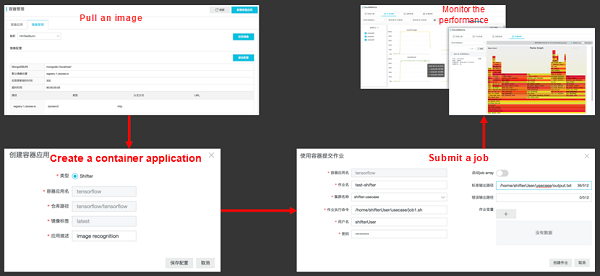
Singularity Deployment Cases
Case 1: Run the NAMD Container Job on Multiple SCC Nodes
NAMD is a type of mainstream MD simulation software featuring good scalability and high parallel efficiency. It is often used to process large-scale molecular systems. In the following description, we assume that a Singularity image containing Intel MPI, NAMD, and inputfile is created based on the image docker.io/centos:7.2.1511. The PBS scheduler is used to submit the NAMD container job and a local job sequentially to four SCC nodes (ecs.scch5.16xlarge, Intel Xeon (Skylake) Gold 6149, 3.1 GHz, 32 physical cores, and 192 GB). The PBS job script is as follows:
#!/bin/sh
#PBS -l ncpus=32,mem=64gb
#PBS -l walltime=20:20:00
#PBS -o namd_local_pbs.log
#PBS -j oe# Run the job in the Singularity container
/opt/intel/impi/2018.3.222/bin64/mpirun --machinefile machinefile -np 128 singularity exec --bind /usr --bind /sys --bind /etc /opt/centos7-intelmpi-namd.sif /namd-cpu/namd2 /opt/apoa1/apoa1.namd# Run the job on the local host
/opt/intel/impi/2018.3.222/bin64/mpirun --machinefile machinefile -np 128 /opt/NAMD_2.12_Linux-x86_64-MPI/namd2 apoa1/apoa1.namd
To differences in CPU usage, RoCE network bandwidth, and software execution efficiency between running NAMD in the container and running NAMD directly on the host, the performance monitoring tool CloudMetrics that comes with E-HPC is used to monitor the usage of SCC cluster resources. The functions of CloudMetrics have been introduced in previous articles, particularly GROMACS and WRF. The following figure shows the resource usage information for each node.
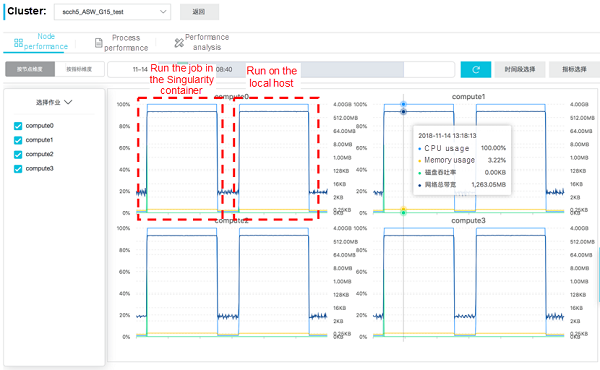
As shown in this figure, the cluster resource usage is basically the same no matter whether NAMD is executed in the container or directly on the host. That is, the CPU is fully loaded and the RoCE network bandwidth remains at about 1.3 Gbit/s on each of the four nodes. The job execution times are 1324s and 1308s, respectively. This result indicates that Singularity is not only highly adapted to the host scheduler, MPI parallel library, and RoCE network, but also can ensure efficient execution of container jobs. The performance loss is less than 2% if container jobs are executed in Singularity, instead of on the host.
Case 2: Run the TensorFlow Image Classification Container Job on an EGS Instance
CIFAR-10 is a classic dataset in the image recognition field. In the following description, it is assumed that a Singularity and a Docker container that contain the image classification model are created based on the image docker.io/tensorflow/tensorflow: latest-devel-gpu-py3. Based on these two containers, training is carried out on a single EGS node (ecs.gn5-c8g1.4xlarge, Intel Xeon E5–2682v4, 2.5 GHz, 16 vCPUs, 120 GB, and 2 P100s). The command lines are as follows:
# Run the job in the Singularity container
singularity exec --nv /opt/cifar10.sif python /cifar10/models/tutorials/image/cifar10/cifar10_multi_gpu_train.py --num_gpus=2# Run the job in the Docker container
nvidia-docker run -it d6c139d2fdbf python /cifar10/models/tutorials/image/cifar10/cifar10_multi_gpu_train.py --num_gpus=2
CloudMetrics is used to monitor the jobs. The following figure shows the resource usage information of the node.
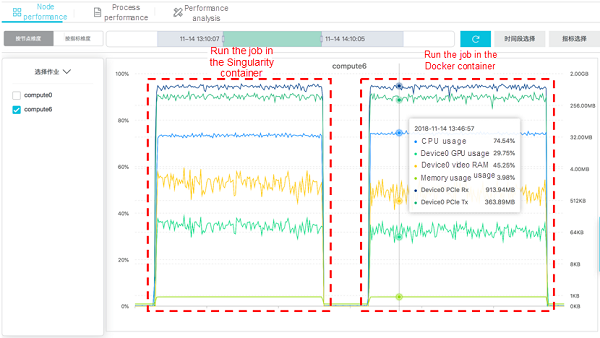
As shown in the figure, no significant difference is found in the resource usage when training of the TensorFlow image classification model is conducted in the Singularity or Docker container. The CPU usage remains at 75%, and the usage of a single GPU ranges from 30% to 40%. Regarding the training efficiency, the training durations for 100,000 steps are 1432s and 1506s, respectively. This indicates that the Singularity container is not only highly adapted to the host GPU and CUDA, and but also has slightly higher job execution efficiency than the Docker container.
Conclusion
Alibaba Cloud Super Computing Cluster integrates the open source Singularity container technology to deliver an efficient and easy-to-use on-cloud elastic high performance container solution. This solution greatly reduces users’ cloud migration costs and improves their scientific research efficiency.
