Building an Enterprise-Level Real-Time Data Lake Based on Flink and Iceberg

By Hu Zheng (Ziyi) is an Alibaba Technical Expert
Apache Flink is a popular unified stream-batch computing engine in the big data field. Data Lake is a new technical architecture in the cloud era. In this article, we will discuss the following question, “What will happen when Apache Flink meets the Data Lake?”
Background and Introduction to Data Lake
What is the data lake? Generally, we maintain all the data generated by an enterprise on one platform, which is called the Data Lake.
Take a look at the following figure. The data sources of this lake are various. Some may be structured data, some may be unstructured data, and some may even be binary data. There is a group of people standing at the entrance of the lake, using equipment to test the water quality. This corresponds to the streaming processing operations on the Data Lake. There is a batch of pumps pumping water from the lake, which corresponds to the batch processing in the Data Lake. There are also a group of people fishing in the boat or on the shore. This represents data scientists extracting data value from the Data Lake through machine learning.

A data lake has four main features:
- Variously sourced storage of raw data
- Supports multiple computing models
- Perfected data management capabilities — Various data sources can be accessed, different data sources can be connected, and schema management and permission management can be supported.
- Flexible bottom-layer storage — Cost-effective distributed file systems like S3, OSS, and HDFS are adopted. The data analysis requirements of corresponding scenarios are met with specific file formats and caches.

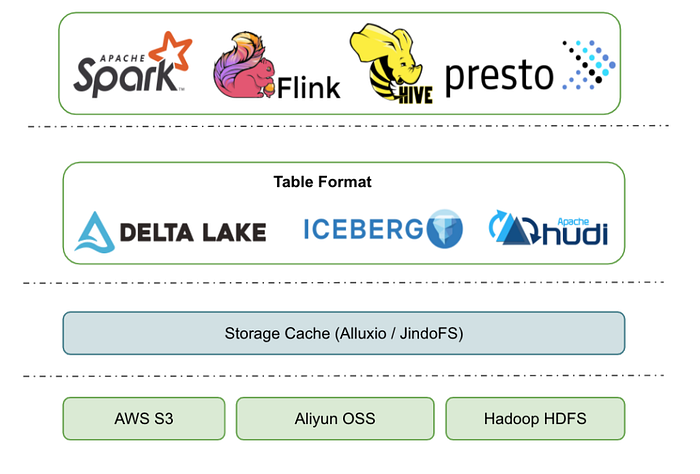
What is the typical open-source Data Lake architecture? The architecture diagram is divided into four layers:
- The bottom is the distributed file system. S3 and OSS tend to be used more by users on the cloud because they are much cheaper. Non-cloud users generally use self-maintained HDFS.
- The second layer is the data acceleration layer. The Data Lake architecture is a complete storage-compute separation architecture. If all data accesses remotely read the data from the file system, performance spending and costs will be high. If some frequently accessed hotspot data can be cached locally on the computing node, the hot and cold separation is implemented naturally. Thus, good local read performance is achieved, and the bandwidth for remote access is saved. At this layer, the open-source Alluxio or Alibaba Cloud JindoFS is often selected.
- The third layer is the Table Format layer. It encapsulates a batch of data files into a business table and provides table-level semantics, such as ACID, snapshot, schema, and partition. It generally uses open-source Delta, Iceberg, Hudi, and other projects. For some users, Delta, Iceberg, and Hudi are considered to be data lakes. These projects are only part of the Data Lake architecture. Since they are closest to users, many details at the bottom are blocked. This is what causes the misunderstanding.
- The top layer is the computing engine for different computing scenarios. Open-source engines include Spark, Flink, Hive, Presto, Hive MR, and others. These computing engines can access tables in the same data lake at the same time.
Introduction to Typical Service Scenarios
What are the typical application scenarios for the combination of Flink and Data Lake? Here, the Apache Iceberg is our Data Lake model by default when discussing business scenarios.

First, a typical Flink + Iceberg scenario is to build a real-time Data Pipeline. A large amount of log data is imported into message queues, such as Kafka. After the Flink streaming computing engine executes ETL operations, the data is imported to the Apache Iceberg original table. In some business scenarios, analysis jobs are completed directly to analyze data in the original table, while in other business scenarios, the data needs to be purified. Thus, a new Flink job is created to consume the incremental data from the Apache Iceberg table. After being processed, the data is written to the purified Iceberg table. Now, the data may also need to be aggregated in other services. Then, the incremental Flink job can be started on the Iceberg table, and the aggregated data is written to the aggregation table.
Some people may think that this scenario can also be implemented through Flink + Hive. It is true. However, the data written to Hive is more for data analysis in the data warehouse rather than incremental data pulling. Generally, Hive writes incremental data for more than 15 minutes with partition as the unit. The long-term high-frequency Flink writes may cause partition expansion. Iceberg allows one minute or even 30 seconds of incremental data writing, which can improve the real-time feature of end-to-end data. The updated data is available on the upper layer analysis job, and the downstream incremental job can read the updated data.
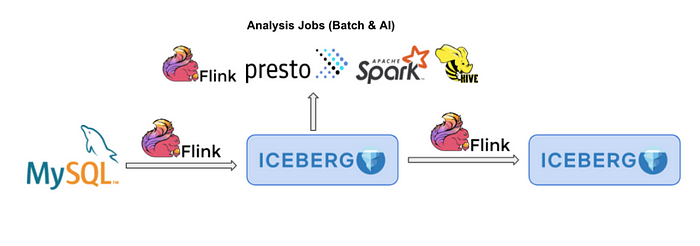
The second typical analysis scenario uses Flink + Iceberg to analyze binlogs of relational databases, such as MySQL. On the one hand, Apache Flink supports CDC data parsing natively. After a piece of binlog data is pulled through ververica flink-cdc-connector, it is automatically converted to four types of messages (INSERT, DELETE, UPDATE_BEFORE, and UPDATE_AFTER) for further real-time computing. Flink Runtime can recognize these four types of messages.
On the other hand, Apache Iceberg has fully implemented the equality delete feature. After the to-be-deleted records are defined by users, they can be written directly to the Apache Iceberg table to delete the corresponding rows. This feature is designed to realize the streaming deletion of the Data Lake. In future versions of Iceberg, users will not need to design any additional business fields. The streaming importing of binlog to Apache Iceberg can be realized with only a few lines of code. The Pull Request of the community has provided a prototype for Flink to write CDC data.
After the CDC data is migrated into Iceberg, the common computing engines will also be connected, such as Presto, Spark, and Hive. All these engines can read the latest data in the Iceberg table in real-time.

The third typical scenario is the stream-batch unification of near real-time scenarios. In the Lambda architecture, there is a real-time procedure and an offline procedure. Generally, the real-time procedure consists of components, such as Flink, Kafka, and HBase, while the offline procedure consists of components, such as Parquet and Spark. Many computing and storage components are involved, resulting in high system maintenance and business development costs. There are many scenarios with fewer real-time requirements. For example, minute-level processing is also allowed. These scenarios are called near real-time scenarios. So, what about optimizing the commonly used Lambda architecture with Flink + Iceberg?

As shown in the preceding figure, we can use Flink + Iceberg to optimize the entire architecture. Real-time data can be written to the Iceberg table through Flink. In the near real-time procedure, incremental data can still be calculated through Flink. In the offline procedure, a snapshot can also be read for global analysis through Flink batch computing. By doing so, corresponding analysis results can be read and analyzed by users in different scenarios. With these improvements, Flink is used as the computing engine and Iceberg as the storage component uniformly. This reduces the maintenance and development costs of the entire system.

In the fourth typical scenario, full data from Iceberg and incremental data from Kafka are used to bootstrap a new Flink job. Assume that an existing streaming job is running online. One day, a business team comes and says they have a new computing scenario and need a new Flink job. They need the job to run the historical data from last year and to connect to the Kafka incremental data being generated. What should we do at this time?
The common Lambda architecture can also be used. The offline procedure is written to the data lake through Kafka :arrow_right: Flink :arrow_right: Iceberg. Due to the high cost of Kafka, the data for the last seven days can be retained. The storage cost of Iceberg is low, so it can store the full historical data, which is split into multiple data partitions by a checkpoint. When starting a new Flink job, the data from Iceberg needs to be pulled from Iceberg and then connected to the data from Kafka.
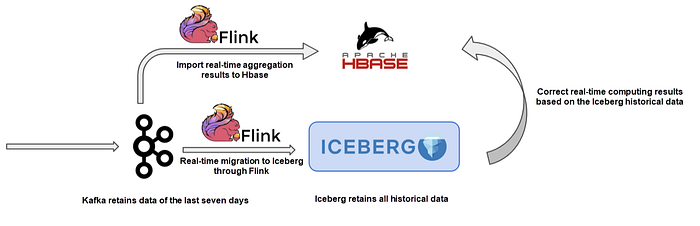
The fifth scenario is similar to the fourth scenario. Similarly, in the Lambda architecture, due to missing events or arrival sequence in the real-time procedure, results at the streaming computing end may not be accurate. In this case, the real-time computing results should be corrected based on the full historical data. Iceberg can play this role well because it can manage historical data with low costs.
Why Apache Iceberg?
Let’s go back to a question left over from the previous section. Why was Apache Iceberg chosen among many open-source data lake projects in Flink at that time?
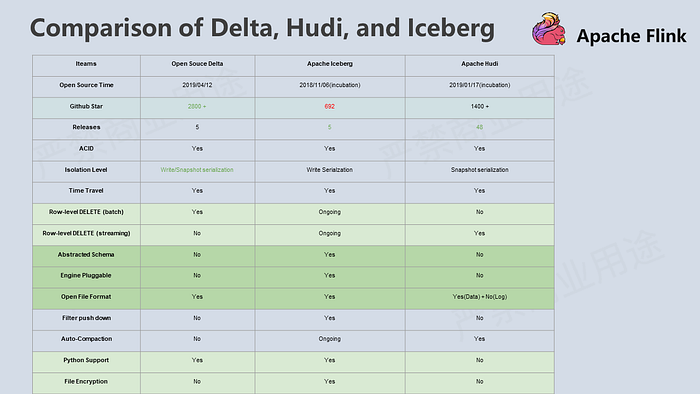
At that time, we investigated Delta, Hudi, and Iceberg and wrote a research report. We found that Delta and Hudi were too deeply bound to the Spark code path, especially the write path. The two projects were more or less initially designed with Spark as the default computing engine. However, Apache Iceberg aimed to make a universally used Table Format. Therefore, it decouples the computing engine from the underlying storage system perfectly and allows easy access to diversified computing engines and file formats. It implements the Table Format layer in the Data Lake architecture correctly. We also think it is easier for Apache Iceberg to become the de facto open-source standard for the Table Format layer.
In addition, Apache Iceberg is developing towards the data lake storage layer with stream-batch unification. The design of manifest and snapshot effectively isolates changes in different transactions, making it convenient for batch processing and incremental computing. Apache Flink is already a computing engine with stream-batch unification. The long-term plans of Iceberg and Flink are perfectly matched. In the future, they will work together to build a data lake architecture with stream-batch unification.
We also found that there are a variety of community resources behind Apache Iceberg. Netflix, Apple, Linkedin, Abroad, and other companies all have PB-level data running on Apache Iceberg. In China, enterprises, such as Tencent, also run huge amounts of data on Apache Iceberg. In their largest business, dozens of TB of incremental data are written into Apache Iceberg every day. Apache Iceberg also has many senior community members with seven Apache PMCs and one VP from other projects. As a result, the requirement for reviewing code and design is very high. A relatively large PR task may return more than 100 comments. In my opinion, all these things guarantee the high quality design and code of Apache Iceberg.
Based on the considerations above, Apache Flink finally chose Apache Iceberg as its first data lake access project.
Implementing Streaming Migration to the Data Lake Using Flink and Iceberg
Currently, streaming and batch lake migration of Flink has been implemented in Apache Iceberg 0.10.0. The Flink batch tasks can query for data in the Iceberg data lake. For more information about how Flink reads and writes Apache Iceberg tables, please see the Apache Iceberg documentation.
The following briefly explains the design principle of the Flink Iceberg Sink. Iceberg uses the optimistic lock method to commit a transaction. When two people submit changing transactions to the Iceberg at the same time, the latter transaction will keep trying to submit. The latter party reads metadata and submits the transaction after the first party submits the transaction successfully. Therefore, it is inappropriate to submit transactions using multiple concurrent operators, which may result in a large number of transaction conflicts and retrying.
We split the Flink write process into two operators to solve this problem, IcebergStreamWriter and IcebergFilesCommitter. IcebergStreamWriter is mainly used to write records to the corresponding avro, parquet, and orc files and to generate a corresponding Iceberg DataFile to be delivered to downstream operators. IcebergFilesCommitter is mainly used to collect all DataFiles into a checkpoint and submit the transaction to Apache Iceberg. The checkpoint data write is done.
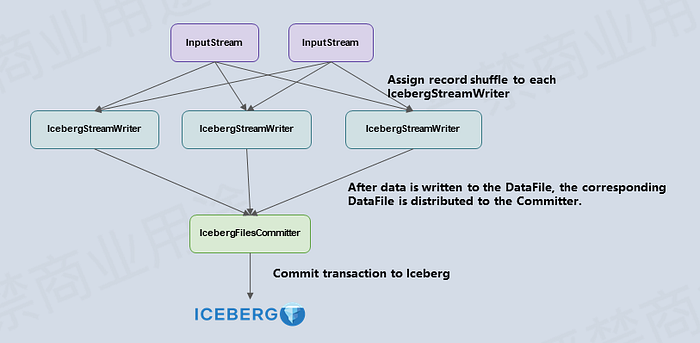
After learning the design of the Flink Sink operators, the next question is, How can we design the state of these two operators correctly?
The design of IcebergStreamWriter is relatively simple. The main task of this design is to convert records into Datafiles. There is no complex State that needs to be designed. IcebergFilesCommitter is a bit more complex. It maintains a DataFile list for each checkpointId and map>. Even if the transaction of a checkpoint fails to be submitted, its DataFiles are still maintained in the State. Data can still be submitted to the Iceberg table through subsequent checkpoints.
Future Community Planning
The release of Apache Iceberg 0.10.0 started the integration of Apache Flink and Apache Iceberg. There will be more advanced functions and features for the future releases of Apache Iceberg 0.11.0 and 0.12.0.
Apache 0.11.0 is designed to solve two main problems:
The first one is the merging of small files. Apache Iceberg 0.10.0 already supports Flink batch jobs to merge small files regularly, which is still in the initial stage. Version 0.11.0 will include a function to merge small files automatically. In other words, there will be a special operator to merge small files after the Flink checkpoint arrives and the Apache Iceberg transaction is submitted.
The second one is the development of the Flink streaming reader. Currently, we have completed some PoC works in the private warehouse. In the future, we will provide a Flink streaming reader in the Apache Iceberg community.
Version 0.12.0 will solve the problem of row-level deletion. As mentioned earlier, we have implemented the full-procedure data lake updating through the Flink UPSERT in the PR 1663. After the community has reached an agreement, the function will be promoted to the community version gradually. Users will be able to write and analyze CDC data in real-time through Flink and upsert Flink aggregation results into Apache Iceberg easily.
About the Author
Hu Zheng (Ziyi) is an Alibaba Technical Expert. He is currently responsible for the design and development of the Flink Data Lake solution, a long-term active contributor to Apache Iceberg and Apache Flink projects, and the author of HBase Principles and Practices.
