Detailed Explanation of Guava RateLimiter’s Throttling Mechanism
Throttling is one of the three effective methods for protecting a high concurrency system. The other two are respectively caching and downgrading. Throttling is used in many scenarios to limit the concurrency and the number of requests. For example, in the event of flash sales, throttling protects your own system and the downstream system from being overwhelmed by tremendous amounts of traffic.
The purpose of throttling is to protect the system by restricting concurrent access or requests, or restricting requests of a specified time window. After the threshold is exceeded, denial of service or traffic shaping is triggered.
Common throttling methods are: 1. Limit the total concurrency. For example, you can limit the size of the database connection pool and thread pool. 2. Limit the instantaneous concurrency. For example, the limit_conn_module of NGINX is used to limit the instantaneously concurrent connections. The Semaphore class of Java can implement the same. 3. Limit the average access rate of a time window. For example, the RateLimiter of Guava and the limit_req module of NGINX can both be used to limit the average access rate per second. 4. Limit the remote API invocation rate. 5. Limit the MQ consumption rate. In addition, we can also implement throttling according to the number of network connections, network traffic, and CPU or memory load.
For example, if we need to limit the concurrency that a method is called simultaneously to less than 100, we can implement it through Semaphore. If we want to limit the average number of times that a method is called during a period to less than 100, we need to use RateLimiter.
Throttling Algorithms
There are two commonly used algorithms for throttling: the leaky bucket algorithm and token bucket algorithm.
You can see from the preceding figure that the water enters the leaky bucket first like the access traffic. Then the water drips out of the bucket like how our system processes the requests. When the water (access traffic) inflows too fast, the bucket gets filled up and then overflows.
The implementation of the leaky bucket algorithm usually relies on the queue. If your system receives a new access request and the queue is not full, it puts the request into the queue. A processor pulls requests from the queue and processes it at a fixed frequency. If the volume of the inbound access requests is too large and the queue becomes full, new requests will be discarded.
The token bucket algorithm works like a bucket that stores a fixed number of tokens, where tokens are added to it at a fixed rate. After the maximum number of tokens stored in the bucket is exceeded, new tokens are discarded or denied. When traffic or network requests arrive, each request must obtain a token. Requests with tokens are processed directly, and one token is removed from the bucket for each request processed. Requests that fail to obtain tokens will be limited: to be directly discarded or wait in the buffer area.
Comparison between the token bucket and the leaky bucket:
- Tokens are added to the token bucket at a fixed rate. Whether a request can be processed depends on whether sufficient tokens are available in the bucket. When the number of available tokens is reduced to zero, all new requests are denied. The leaky bucket processes requests at a fixed rate. The rate of inbound requests is not limited, but when the accumulated amount of inbound requests exceeds the maximum capacity of the bucket, new inbound requests are denied.
- The token bucket limits the average inflow rate and allows sudden increase in traffic. The request can be processed as long as it has a token. Three or four tokens can be given at one time. The leaky bucket limits the constant outflow rate, which is set to a fixed value. For example, if the outflow rate is set to one request per second, it cannot process two requests per second. This ensures the outflow rate is always stable, regardless of the inflow rate.
- The token bucket allows for sudden increase in traffic to some extent, while the leaky bucket is mainly used to ensure the smooth outflow rate.
Guava RateLimiter
Guava is an excellent open-source Java project. It contains several core libraries of Google that are used in their Java-based projects: collections, caching, concurrency libraries, common annotations, string processing, I/O, and so forth.
Guava RateLimiter provides the token bucket algorithm implementations: SmoothBursty and SmoothWarmingUp.
The class diagram of RateLimiter is provided in the preceding figure, where the RateLimiter class provides two factory methods to create two subclasses. This is in line with the idea to replace constructors by using statistic factory methods. This idea was proposed by the book Effective Java, the author of which is one of the main maintainers of Guava libraries.
// RateLimiter provides two factory methods. At last, the following two functions will be called to generate two subclasses of RateLimiter.
static RateLimiter create(SleepingStopwatch stopwatch, double permitsPerSecond) {
RateLimiter rateLimiter = new SmoothBursty(stopwatch, 1.0 /* maxBurstSeconds */);
rateLimiter.setRate(permitsPerSecond);
return rateLimiter;
}
static RateLimiter create(
SleepingStopwatch stopwatch, double permitsPerSecond, long warmupPeriod, TimeUnit unit,
double coldFactor) {
RateLimiter rateLimiter = new SmoothWarmingUp(stopwatch, warmupPeriod, unit, coldFactor);
rateLimiter.setRate(permitsPerSecond);
return rateLimiter;
}SmoothBursty
Use a static method of RateLimiter to create a limiter, and set the number of tokens to be placed into the bucket to five. The returned RateLimiter object ensures that no more than five tokens will be placed into the bucket every second at a fixed rate, to smooth the outflow traffic.
public void testSmoothBursty() {
RateLimiter r = RateLimiter.create(5);
while (true) {
System.out.println("get 1 tokens: " + r.acquire() + "s");
}
/**
* output: Basically, the limiter is executed every 0.2s, which complies with the setting of releasing five tokens per second.
* get 1 tokens: 0.0s
* get 1 tokens: 0.182014s
* get 1 tokens: 0.188464s
* get 1 tokens: 0.198072s
* get 1 tokens: 0.196048s
* get 1 tokens: 0.197538s
* get 1 tokens: 0.196049s
*/
}RateLimiter uses the token bucket algorithm and accumulates the tokens. If the token consumption frequency is low, the requests can directly get the tokens without waiting.
public void testSmoothBursty2() {
RateLimiter r = RateLimiter.create(2);
while (true)
{
System.out.println("get 1 tokens: " + r.acquire(1) + "s");
try {
Thread.sleep(2000);
} catch (Exception e) {}
System.out.println("get 1 tokens: " + r.acquire(1) + "s");
System.out.println("get 1 tokens: " + r.acquire(1) + "s");
System.out.println("get 1 tokens: " + r.acquire(1) + "s");
System.out.println("end");
/**
* output:
* get 1 tokens: 0.0s
* get 1 tokens: 0.0s
* get 1 tokens: 0.0s
* get 1 tokens: 0.0s
* end
* get 1 tokens: 0.499796s
* get 1 tokens: 0.0s
* get 1 tokens: 0.0s
* get 1 tokens: 0.0s
*/
}
}RateLimiter accumulates tokens to allow it to cope with sudden increase in traffic. In the following snippet, a thread will directly acquire five tokens. The request will be quickly responded, because the token bucket has the sufficient number of accumulated tokens.
When RateLimiter does not have sufficient number of tokens available, it uses the delayed processing method. The period of time that the current thread ought wait to acquire a token is assumed by the next thread. In other words, the next thread waits additional time on behalf of the current thread.
public void testSmoothBursty3() {
RateLimiter r = RateLimiter.create(5);
while (true)
{
System.out.println("get 5 tokens: " + r.acquire(5) + "s");
System.out.println("get 1 tokens: " + r.acquire(1) + "s");
System.out.println("get 1 tokens: " + r.acquire(1) + "s");
System.out.println("get 1 tokens: " + r.acquire(1) + "s");
System.out.println("end");
/**
* output:
* get 5 tokens: 0.0s
* get 1 tokens: 0.996766s As a result of the delayed processing method, this thread waits for additional time on behalf of a previous thread.
* get 1 tokens: 0.194007s
* get 1 tokens: 0.196267s
* end
* get 5 tokens: 0.195756s
* get 1 tokens: 0.995625s As a result of the delayed processing method, this thread waits for additional time on behalf of a previous thread.
* get 1 tokens: 0.194603s
* get 1 tokens: 0.196866s
*/
}
}SmoothWarmingUp
The RateLimiterSmoothWarmingUp method has a warm-up period after teh startup. It gradually increases the distribution rate to the configured value.
For example, you can use the following snippet to create a ratelimiter with an average token creation rate of 2 tokens/s, and a warm-up period of 3 seconds. The token bucket does not create a token every 0.5 seconds immediately after startup, because a warm-up period of 3 seconds has been set. Instead, the system gradually increases the token creation rate to the pre-set value within 3 seconds, and then creates tokens at a fixed rate. This feature is suitable for scenarios where the system needs some time to warm up after startup.
public void testSmoothwarmingUp() {
RateLimiter r = RateLimiter.create(2, 3, TimeUnit.SECONDS);
while (true)
{
System.out.println("get 1 tokens: " + r.acquire(1) + "s");
System.out.println("get 1 tokens: " + r.acquire(1) + "s");
System.out.println("get 1 tokens: " + r.acquire(1) + "s");
System.out.println("get 1 tokens: " + r.acquire(1) + "s");
System.out.println("end");
/**
* output:
* get 1 tokens: 0.0s
* get 1 tokens: 1.329289s
* get 1 tokens: 0.994375s
* get 1 tokens: 0.662888s The total amount of time that has been taken for acquiring these three tokens is 3s.
* end
* get 1 tokens: 0.49764s Tokens are acquired at the normal rate of two tokens/s.
* get 1 tokens: 0.497828s
* get 1 tokens: 0.49449s
* get 1 tokens: 0.497522s
*/
}
}Source Code Analysis
After getting familiar with the basic usage of the RateLimiter, let us learn about how it is implemented. First, take a look at several important variables and their definitions.
//SmoothRateLimiter.java
//The number of currently stored tokens
double storedPermits;
//The maximum number of stored tokens
double maxPermits;
//The interval to add tokens
double stableIntervalMicros;
/**
* The time for the next thread to call the acquire() method
* RateLimiter allows preconsumption. After a thread preconsumes any tokens,
the next thread needs to wait until nextFreeTicketMicros to acquire tokens.
*/
private long nextFreeTicketMicros = 0L;SmoothBursty
Every time the acquire() method is called, RateLimiter compares the current time with the nextFreeTicketMicros, and refreshes the number of stored tokens storedPermits based on the difference between them and the interval for adding a unit number of tokens stableIntervalMicros. Then the acquire()method sleeps until nextFreeTicketMicros.
The snippet for the acquire() method is provided as follows. The acquire() method calls the reserve function to calculate the period of time that is required for acquiring the target number of tokens. Then it calls the SleepStopwatch method to sleep and return the period off time to be waited.
public double acquire(int permits) {
// Calculate the period of time that the next thread must wait to call the acquire() method
long microsToWait = reserve(permits);
// Put the thread into sleep
stopwatch.sleepMicrosUninterruptibly(microsToWait);
return 1.0 * microsToWait / SECONDS.toMicros(1L);
}
final long reserve(int permits) {
checkPermits(permits);
// Concurrent operations are performed, so the synchronized() method is used.
synchronized (mutex()) {
return reserveAndGetWaitLength(permits, stopwatch.readMicros());
}
}
final long reserveAndGetWaitLength(int permits, long nowMicros) {
// Calculate the earliest time for acquiring the target number of tokens starting from the current time.
long momentAvailable = reserveEarliestAvailable(permits, nowMicros);
// Calculate the difference between the two time, and determine the period that the next thread needs to wait
return max(momentAvailable - nowMicros, 0);
}reserveEarliestAvailable is the key function for refreshing the number of tokens and the time for acquiring the next token nextFreeTicketMicros. Three steps are involved in this process. Step 1: Call the resync function to add tokens. Step 2: Calculate the additional time that the thread must wait after it was preconsumed for the specified number of tokens. Step 3: Update the time that the next token can be acquired nextFreeTicketMicrosand the number of stored tokens storedPermits.
The preconsumption feature of RateLimiter is involved in this case. RateLimiter allows a thread to preconsume tokens without waiting. To acquire tokens, the next thread must wait for an additional period for the preconsumed tokens. For detailed explanation of the coding logic, see the following comments:
final long reserveEarliestAvailable(int requiredPermits, long nowMicros) {
// Refresh the number of tokens. This is done every time the acquire() method is called.
resync(nowMicros);
long returnValue = nextFreeTicketMicros;
// Compare the number of available tokens and the target number of tokens that need to be acquired to calculate the number of tokens that can be acquired for the moment.
double storedPermitsToSpend = min(requiredPermits, this.storedPermits);
// freshPermits refers to the number of tokens that need to be preconsumed, which is equal to the target number of tokens minus the number of currently available tokens.
double freshPermits = requiredPermits - storedPermitsToSpend;
// When the number of available tokens is smaller than the target number of tokens needed, some tokens will be preconsumed.
// waitMicros is the period of time required for the preconsumed tokens. watiMicros should be added to the time that the next thread originally needs to wait without considering the preconsumption.
long waitMicros = storedPermitsToWaitTime(this.storedPermits, storedPermitsToSpend)
+ (long) (freshPermits * stableIntervalMicros);
// The implementation of storedPermitsToWaitTime in SmoothWarmingUp is different from that in SmoothBursty. It is used to implement the warm-up period.
// In SmoothBursty, storedPermitsToWaitTime directly returns 0. Therefore, waitMicros is the period of time that is required for the preconsumed tokens.
try {
//Update nextFreeTicketMicros. The period of time required for preconsumed tokens should be assumed by the next thread.
this.nextFreeTicketMicros = LongMath.checkedAdd(nextFreeTicketMicros, waitMicros);
} catch (ArithmeticException e) {
this.nextFreeTicketMicros = Long.MAX_VALUE;
}
// Update the number of tokens. The minimum value is 0.
this.storedPermits -= storedPermitsToSpend;
// Return the value of the original nextFreeTicketMicros. No need to wait additional time for preconsumed tokens.
return returnValue;
}
// SmoothBurest
long storedPermitsToWaitTime(double storedPermits, double permitsToTake) {
return 0L;
}The resync function is used to increase the number of stored tokens. Its core logic is (nowMicros - nextFreeTicketMicros) / stableIntervalMicros. Refresh when the current time is greater than nextFreeTicketMicros, or directly return.
void resync(long nowMicros) {
// The current time is greater than nextFreeTicketMicros, so it refreshes tokens and nextFreeTicketMicros.
if (nowMicros > nextFreeTicketMicros) {
// The coolDownIntervalMicros function generates a token per a specified number of seconds. Its implementation in SmoothWarmingUp is different than that in SmoothBursty.
// The coolDownIntervalMicros of SmoothBursty directly returns stableIntervalMicros.
// Deduct the time for refreshing tokens from the current time to determine the difference. Divide the difference with the token-adding-interval to determine the number of tokens that need to be added during this period of time.
storedPermits = min(maxPermits,
storedPermits
+ (nowMicros - nextFreeTicketMicros) / coolDownIntervalMicros());
nextFreeTicketMicros = nowMicros;
}
// If the current time is earlier than nextFreeTicketMicros, the thread that needs to acquire the token must wait until nextFreeTicketMicros.
The additional wait time is added to the next thread that needs to acquire the token.
}
double coolDownIntervalMicros() {
return stableIntervalMicros;
}Here is an example that may help you better understand the logic of the resync and reserveEarliestAvailablefunctions.
For example, stableIntervalMicros of RateLimiter is 500, which means it generates two tokens per second. The storedPermits is 0, and the nextFreeTicketMicros is 1553918495748. Thread 1 calls acquire(2). The current time is 1553918496248. First, call the resync function to calculate the number of tokens that can be acquired, which is (1553918496248 - 1553918495748)/500 = 1. Ratelimiter supports preconsumption, so nextFreeTicketMicros= nextFreeTicketMicro + 1 × 500 = 1553918496748. Thread 1 does not have to wait.
Then Thread 2 calls acquire(2). First, the resync function finds that the current time is earlier than nextFreeTicketMicros, so it cannot add new tokens. Therefore, two tokens need to be preconsumed, and nextFreeTicketMicros= nextFreeTicketMicro + 2 × 500 = 1553918497748. Thread 2 needs to wait until 1553918496748, which is equal to nextFreeTicketMicros calculated for Thread 1. Thread 3 also needs to wait until nextFreeTicketMicros calculated for Thread 2.
SmoothWarmingUp
Next, let us take a look at how the SmoothWarmingUp rate limiter is implemented.
The main difference is the SmoothWarmingUp implementation has a warm-up period, during which the token generation rate and the number of tokens increases with time. This process is illustrated as follows. The token (permit) refresh interval reduces with time. When the number of stored tokens reduces from maxPermits to thresholdPermits, the time cost for creating tokens also reduces from the coldInterval to the normal stableInterval.
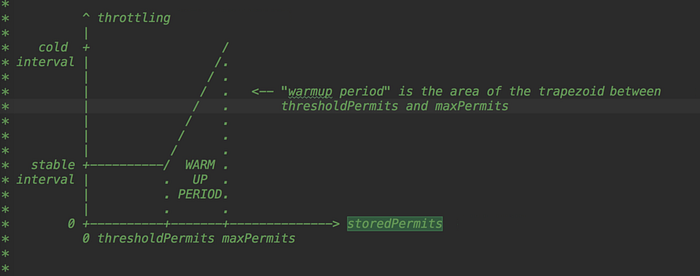
The code snippet of the SmoothWarmingUp rate limiter is provided as follows, and the logic of the code is explained in comments.
// For a SmoothWarmingUp rate limiter, the wait time is the area of the square or the trapezoid in the preceding figure.
long storedPermitsToWaitTime(double storedPermits, double permitsToTake) {
/**
* The number of permits in excess of the thresholdPermits
*/
double availablePermitsAboveThreshold = storedPermits - thresholdPermits;
long micros = 0;
/**
* If the number of the currently stored permits exceeds the thresholdPermits
*/
if (availablePermitsAboveThreshold > 0.0) {
/**
* The number of needed permits in excess of the thresholdPermits
*/
double permitsAboveThresholdToTake = min(availablePermitsAboveThreshold, permitsToTake); /**
* The are of the trapezoid
*
* h × (b1 + b2)/2
*
* where h is permitsAboveThresholdToTake, which is equivalent to the number of permits to be preconsumed
* b2 is the longer base, which is permitsToTime(availablePermitsAboveThreshold)
* b1 is the shorter base, which is permitsToTime(availablePermitsAboveThreshold - permitsAboveThresholdToTake)
*/
micros = (long) (permitsAboveThresholdToTake
* (permitsToTime(availablePermitsAboveThreshold)
+ permitsToTime(availablePermitsAboveThreshold - permitsAboveThresholdToTake)) / 2.0);
/**
* Minus the number of permits in excess of the thresholdPermits (already acquired)
*/
permitsToTake -= permitsAboveThresholdToTake;
}
/**
The area of the stable period equals to length × width
*/
micros += (stableIntervalMicros × permitsToTake);
return micros;
}double coolDownIntervalMicros() {
/**
The number of permits increased per second equals to warmup time/maxPermits. During the warmup period, the number of permits increases to
* maxPermits
*/
return warmupPeriodMicros / maxPermits;
}
Postscript
RateLimiter can only be used in throttling of standalone applications. If you want to implement throttling in a cluster, you need to introduce Redis or an Alibaba open-source middleware sentinel. Stay tuned.
Personal blog: remcarpediem
Official WeChat account: remcarpediem
