Getting Started with Kubernetes | etcd

By Zeng Fansong (Zhuling), Senior Container Platform Technical Expert at Alibaba Cloud
Etcd is a distributed and consistent Key-Value Store (KVStore) used for configuration sharing and service discovery. This article looks at the evolution of etcd to introduce its overall architecture and how it works. I hope this article will help you better understand and use etcd.
1. Development History of etcd
Etcd was initially developed by CoreOS for distributed concurrent control over OS upgrades in cluster management systems and the storage and distribution of configuration files. Therefore, etcd has been designed to provide high-availability and high-consistency small KVStore services.
Etcd is currently affiliated with Cloud Native Computing Foundation (CNCF) and widely used by large Internet companies, such as Amazon Web Services (AWS), Google, Microsoft, and Alibaba.

CoreOS submitted the initial code of the first version to GitHub in June 2013.
In June 2014, Kubernetes V0.4 was released in the community. Kubernetes is a container management platform developed by Google and contributed to the community. It attracted a great deal of attention from the very beginning because it integrates Google’s years of experience in container scheduling and cluster management. Kubernetes V0.4 used etcd V0.2 as the storage service for core experiment metadata. The etcd community has developed rapidly since then.
In February 2015, etcd released V2.0, its first official stable version. In V2.0, etcd redesigned the Raft consensus algorithm, provided a simple tree data view, and supported more than 1,000 writes per second, which met the requirements of most scenarios at that time. After the release of etcd V2.0, its original data storage solution gradually became a performance bottleneck after continuous iteration and improvement. After that, etcd launched the solution design of V3.
In January 2017, etcd released V3.1, which marked the maturity of the etcd technology. etcd V3 provided a new set of APIs, which enabled more efficient consistency read methods and provided a gRPC proxy to improve the read performance of etcd. In addition, the V3 solution contained a lot of GC optimizations, supporting more than 10,000 writes per second.
In 2018, more than 30 CNCF projects used etcd as their core data storage. In November 2018, etcd became a CNCF incubation project. After entering CNCF, etcd had more than 400 contribution groups, including nine project maintainers from eight companies, such as AWS, Google, and Alibaba.
In 2019, etcd V3.4 was jointly created by Google and Alibaba, which further improved the performance and stability of etcd to cope with the demanding scenarios of ultra-large companies.
2. Architecture and Internal Mechanism Analysis
Overall Architecture
Etcd is a distributed and reliable KVStore system used to store key data in a distributed system.

An etcd cluster consists of three or five nodes. Multiple nodes cooperate with each other through the raft consensus algorithm. The algorithm elects a master node as the leader, which is responsible for data synchronization and distribution. When the leader fails, the system automatically elects another node as the leader to complete data synchronization again. Only one of the nodes needs to be selected to read and write data, while etcd completes the internal status and data collaboration.
Quorum is a key concept in etcd. It is defined as (n+1)/2, indicating that more than half of the nodes in the cluster constitute a quorum. In a three-node cluster, etcd still runs as long as any two nodes are available. Similarly, in a five-node cluster, etcd still runs as long as any three nodes are available. This is the key to the high availability of the etcd cluster.
To enable etcd to continue running after some nodes fail, the complex problem of distributed consistency must be solved. In etcd, the distributed consensus algorithm is implemented by the Raft consensus algorithm. The following briefly describes the algorithm. The Raft consensus algorithm can work only when any two quorums have a shared member. That is, any alive quorum must contain a shared member that contains all confirmed and submitted data in the cluster. Based on this principle, a data synchronization mechanism is designed for the Raft consensus algorithm to synchronize all the data submitted by the last quorum after the leader is changed. This ensures data consistency as the cluster status changes.
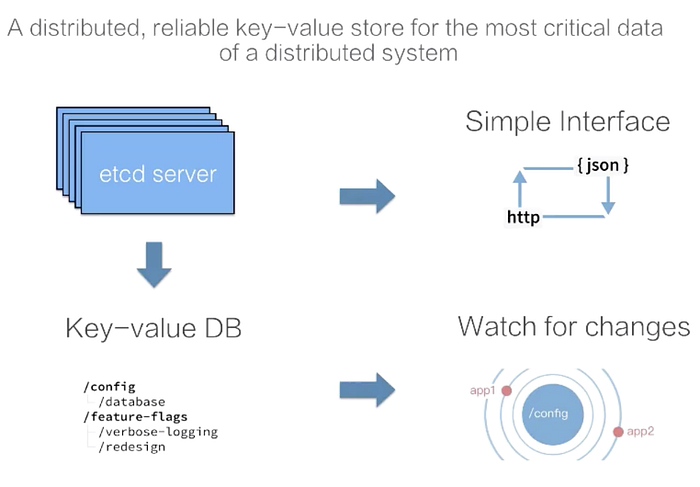
Etcd has a complex internal mechanism but provides simple and direct APIs for customers. As shown in the preceding figure, you can access cluster data through the etcd client, or directly access etcd over HTTP, which is similar to the curl command. Data expression in etcd is simple. You can understand the data storage of etcd as an ordered map that stores key-value data. etcd also provides a watch mechanism to subscribe to data changes for clients. The watch mechanism obtains incremental data updates in etcd in real-time to synchronize data with etcd.
API Introduction
This section describes five groups of APIs provided by etcd.

- Put and Delete: As shown in the preceding figure, the Put and Delete operations are simple. Only a key and a value are required to write data to the cluster, and only the key is required to delete data.
- Get: etcd supports query by a specified key and query by a specified key range.
- Watch: etcd provides a Watch mechanism to subscribe to the incremental data updates in etcd in real time. Watch allows you to specify a key or a key prefix. Generally, the latter option is used.
- Transactions: etcd provides a simple transaction mechanism to perform certain operations when one set of conditions is met or perform other operations when the conditions are not met. This is similar to the if…else statement used in code. etcd ensures the atomicity of all operations.
- Leases: The Leases API is a common design mode in distributed systems.
Data Version Mechanism
To correctly use etcd APIs, you must know the corresponding internal data versions.
etcd uses a term to represent the term of the cluster leader. When the leader changes, the term value increases by 1. The leader changes when the leader fails, the leader’s network connection is abnormal, or the cluster is stopped and restarted.
Revision is the version of global data. When data is created, modified, or deleted, the value of the revision increases by 1. Specifically, the revision always increases globally across the leader terms in a cluster. This feature makes a unique revision available for any change in the cluster. Therefore, you can support Multi-Version Concurrency Control (MVCC) or data Watch based on revisions.
etcd records three versions of each key-value data node:
- create_revision is the revision of the key-value data upon creation.
- mod_revision is the revision upon data operations.
- A counter specifies how many times the key-value data has been modified.
The following figure shows the term and revision changes.
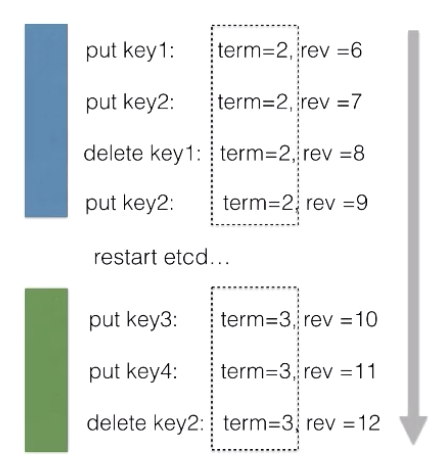
During the term of a leader, the terms values for all modification operations are 2 while the rev values steadily increase by 1 each time. After the cluster is restarted, the term values for all modification operations change to 3. During the term of a new leader, all the term values are 3 and remain unchanged, while the rev values continue to increase by 1 each time. The rev values steadily increase increasing during the terms of two leaders.
MVCC and Streaming Watch
This section describes how to use multiple versions of etcd to implement concurrent control and data subscription (Watch).
In etcd, data can be modified multiple times for the same key, and each data modification corresponds to a version number. etcd records the data of each modification, which means that a key has multiple historical versions in etcd. If you do not specify the version when querying data, etcd returns the latest version of the key. etcd also supports the query of historical data by version.

When using Watch to subscribe to data, you can create a watcher from any historical time or a specified revision to create a data pipeline between the client and etcd. etcd pushes all data changes that have occurred since the specified revision. The Watch mechanism provided by etcd immediately pushes the modified data of the key to the client through the data pipeline.
As shown in the following figure, all the data of etcd is stored in B+ Tree (shown in gray), and the B+ Tree is stored on the disk and mapped to the memory in mmap mode for quick access. The gray B+ Tree maintains the revisions-to-value mappings and supports data query by revision. The revision value steadily increases by 1. Therefore, when you use Watch to subscribe to the data after a specified revision, you only need to subscribe to the data changes of the B+ Tree.

Another B+ Tree (in blue) is maintained in etcd, which manages key-to-revisions mappings. When using a key to query data, the client converts the key into the revision through the blue B+ Tree in blue and then queries the data through the gray B+ Tree.
Etcd records each modification, which leads to continuous data growth, occupies the memory and disk space, and affects the B+ Tree query efficiency. etcd uses a periodic compaction mechanism to clean up the data of multiple historical versions of the same key that were created before a certain time. As a result, the gray B+ Tree continues to steadily increase with some gaps.
Mini Transaction
This section describes the mini transaction mechanism of etcd. The transaction mechanism of etcd is simple. It can be thought of as an if-else program, and multiple operations can be provided in an if statement, as shown in the following figure.

The If Statement contains two conditions. If the value of Value(key1) is greater than that of bar and the value of Version(key1) is 2, run the Then statement to modify the data of key2 to valueX and delete the data of key3. If any condition is not met, change the data of key2 to valueY.
Etcd ensures the atomicity of the entire transaction operation. That is, the views for all comparison conditions in the If statement are consistent. It also ensures the atomicity of multiple operations, which means all operations in the Then statement are performed.
With the transaction mechanism of etcd, you can ensure the data read and write consistency in multiple competitions. For example, the Kubernetes project mentioned earlier uses the transaction mechanism of etcd to ensure the same data is modified consistently on multiple Kubernetes API servers.
Lease
Lease is commonly used to represent a distributed lease in distributed systems. Typically, the lease mechanism is required to detect whether a node is alive in a distributed system.
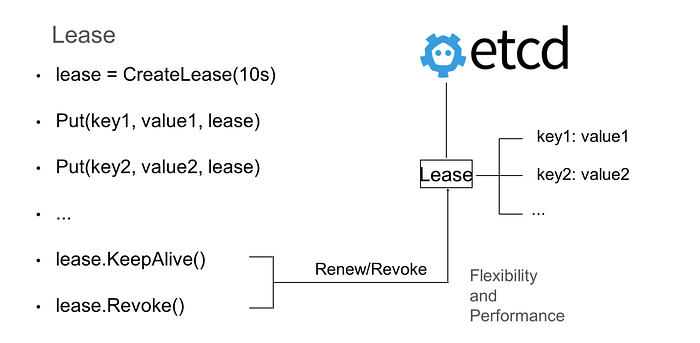
As shown in the preceding figure, a 10-second lease is created. If you do not perform any operations after the lease is created, the lease automatically expires after 10 seconds. Bind key1 and key2 to the lease so that etcd automatically clears key1 and key2 when the lease expires.
If you want to keep the lease, you need to periodically call the KeeyAlive method to refresh it. For example, to check whether a process in a distributed system is alive, you can create a lease in the process and periodically call the KeepAlive method in the process. If the process is normal, the lease on this node is kept. If the process crashes, the lease automatically expires.
However, if a large number of keys need to support a similar lease mechanism, and the lease must be refreshed for each key independently, this puts a great deal of pressure on etcd. Therefore, etcd allows the binding of multiple keys (for example, keys with similar expiration times) to the same lease, which can greatly reduce the overhead of lease refresh and improve etcd performance.
3. Typical Scenarios
Metadata Storage
Kubernetes stores its status data in etcd for high availability. In this way, Kubernetes does not need to perform complex status processing for a distributed system, which greatly simplifies its system architecture.

Service Discovery (Naming Service)
In a distributed system, multiple backends (possibly hundreds of processes) are required to provide a set of peer services, such as the search service and recommendation service.

To reduce the O&M cost of such a backend service (where a faulty node is replaced immediately), the backend process is scheduled by a cluster management system such as Kubernetes. In this way, when a user or an upstream service calls this process, a service discovery mechanism is required to route the service. This service discovery can be efficiently implemented by using etcd:
- After the process is started, the address of the process can be registered with etcd.
- API Gateway can promptly detect the backend process address by using etcd. When a failover occurs, the new process address is registered with etcd, and API Gateway can promptly detect the new address.
- If the serving process crashes, API Gateway can remove its traffic to prevent call timeout by using the etcd lease mechanism.
In this architecture, service status data is taken over by etcd, and API Gateway is stateless and can be scaled out to serve more customers. Thanks to the excellent performance of etcd, tens of thousands of backend processes are supported, allowing this architecture to serve large enterprises.
Distributed Coordination: Leader Election
Distributed systems typically adopt a master+workers design model. Generally, workers nodes provide a variety of resources, such as CPU, memory, disks, and networks, while the master node coordinates these nodes to provide external services, such as distributed storage and distributed computing. Both the typical Hadoop Distributed File System (HDFS) and the Hadoop distributed computing service adopt a similar design model. Such design models have a common problem: availability of the master node. When the master node fails, all services in the cluster stop running and cannot serve users.
The typical solution is to start multiple master nodes. Master nodes contain control logic and status synchronization among multiple nodes is complex. The most typical method is to select a master node as the leader to provide services and leave the other master node in the waiting state.
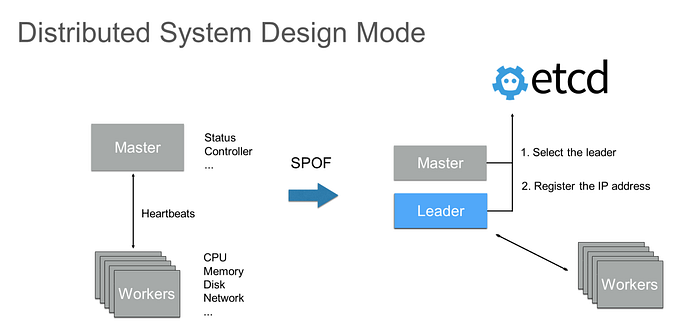
The mechanism provided by etcd can easily implement the leader election function for distributed processes. For example, the leader election logic can be implemented by transaction writing for the same key. Generally, the selected leader registers its IP address with etcd so that workers nodes can promptly obtain the IP address of the current leader and the system can continue to work with only one master node. When an exception occurs on the leader, a new node can be selected as the leader through etcd. After the new IP address is registered, workers nodes can pull the IP address of the new leader to resume the service.
Distributed Coordination: Distributed System Concurrency Control
In a distributed system, when you execute some tasks, such as upgrading the operating system, upgrading software on the operating system, or executing computing tasks, you need to control the task concurrency to prevent a bottleneck in backend services and ensure the business stability. If the task lacks a master node to implement coordination, you can use etcd to do this.
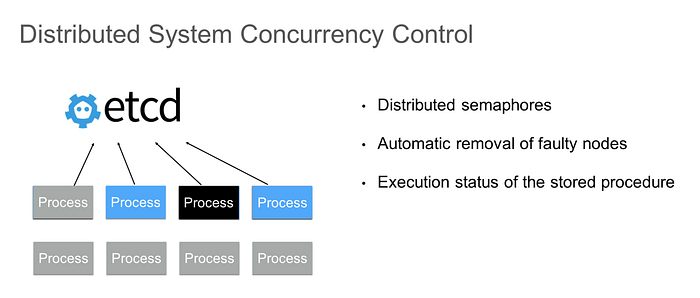
In this mode, you can use etcd to implement a distributed semaphore and use the etcd lease mechanism to automatically remove faulty nodes. If the running cycle of a process is long, you can store some generated status data to etcd. In this way, if the process fails, you can restore some execution statuses from etcd, instead of completing the entire computing logic again. This improves the efficiency of the overall task.
Summary
Let’s summarize what we have learned in this article:
- The first part describes the emergence of etcd and several important moments during its evolution.
- The second part introduces the architecture and basic APIs of etcd, as well as basic etcd data operations and how etcd works.
- The third part describes three typical etcd scenarios and the design ideas of distributed systems in these scenarios.
