In-depth Analysis on HLC-based Distributed Transaction Processing
Implementing distributed transactions is one of the most difficult technologies in the distributed database field. Distributed transactions enable consistent data access in distributed databases, ensure the atomicity and isolation of global reads/writes, and provide users with an integrated experience of distributed databases. This article mainly describes clock solutions in distributed databases and distributed transaction management. Hybrid logical clock (HLC) allows obtaining data locally and avoids performance bottlenecks and single point of failures that would otherwise be caused by centralized clocks. At the same time, HLC preserves the causal relationship (happen before) between events or transactions across instances.
This lecture mainly covers the two following topics:
- Clock solution
- Distributed transaction management

1. Clock Solution
(1) Why Clocks Are Needed in Databases?
The essential goal of databases is to sort transactions. Transaction sorting in a standalone database is easy. However, how are transactions sorted in a distributed system? A database provides the ACID properties for data-related operations through transactions. The transaction sequence identified in a database determines the atomicity and isolation of transactions. Atomicity refers to the completeness of transactions (that is, either all occur, or nothing occurs) and indicates that each transaction is independent. Isolation means that individual transactions are isolated. A clock has different ways of identifying transaction sequence. For example, each log in Oracle has a log sequence number (LSN), transaction ID, and timestamp. Currently, MVCC is supported in many commercial databases and open-source databases. MVCC allows reading/writing the same data to implement concurrency by supporting multiple data versions, significantly improving performance in scenarios where reads are more than writes. Multiversion itself implies the transaction sequence. When a transaction starts, it is required to determine which data version is visible and which is invisible. This involves many aspects including multiple systems, multiple versions, and version recycling. A typical scenario is shopping on Taobao or Tmall. In this scenario, every time a user buys an item, a deduction is made from the item quantity record. Many versions of the item record will be generated over time. It is inappropriate to keep all the versions. Otherwise the entire storage usage would be continuously increasing. So, how can we recycle a version? Sequence is also a concern during recycling. Which versions should be recycled?
(2) Clock in a Distributed Database
What are the differences between clocks in distributed databases and standalone databases? First, sorting in a standalone database is extremely simple: Transaction sequence can be indicated simply by using LSNs or transactions IDs. In a distributed database, each local lock cannot reflect the global transaction sequence because databases are running on multiple servers and each database instance has its independent clock or log (LSN). Clock offset occurs between servers. Ideally, a distributed database deploys 100 nodes and the clocks for the 100 nodes are completely synchronous. However, in practical situations, clock verification is required for off-track operations in a data center. Because clocks across servers have offsets, clocks in distributed databases cannot reflect the global setting.
(3) Clock Solution
Many clock solutions are available, for example, using unified centralized nodes or using independent servers to generate distributed clocks. Another solution is logical time. For example, A Lamport clock is a logical clock. A logical clock means that no centralized nodes are used to generate time and each node has its own local logical time. Consider 10 Oracle databases, each node having its own LSNs. If a node has many transactions, transaction IDs can be processed very fast. If a node has a relatively small number of transactions, processing transaction IDs is relatively slow. The following figure shows several popular clock solutions. Among them, TiDB is the pride of the Chinese developer community. TiDB uses centralized clocks. In addition, Postgres-XL uses GTM, which is also a centralized clock. Oracle adopts the logical clock SCN. CockroachDB is a distributed database that takes Spanner as a model and uses a hybrid logical clock. The well-known database Google Cloud Spanner has a strong dependency on hardware and uses TrueTime. Essentially, TrueTime is an atomic clock, which ensures only a small clock offset between two servers.

(4) Logical Clock
How can we implement logical clocks in distributed databases? As shown in the following figure, each of the three nodes (A, B, and C) has its own logical time. Logical time can be simply seen as a monotonically increasing natural number (for example, 0, 1, 2, and 3). After a transaction starts, the number adds 1. If a new transaction is included, add 1 again. In the entire distributed environment, the three nodes are completely independent and have no correlation with each other. If a transaction is made across multiple nodes and involves interaction across nodes, the local clock also adds 1 if a new transaction is generated. When a message is to be sent, in addition to the message body, the local time also needs to be sent to another node. After a node receives that message, the node needs to process that message and choose the maximum value (either the time or the local logical time) as the local time from the received message. If Node A publishes a transaction relatively fast and needs to process the second transaction after the first transaction is processed, Node A will interact with Node B. At this point, A adds 1 and takes the clock to Node B, which directly skips from 0 to 2. In this way, an association is established between the two clocks to make them consecutive. At this point, the “happen before” relationship is established, representing that the transaction on Node A is completed before the new transaction on Node B starts. In a distributed database, if two transactions do not operate on the same node, the two transactions are irrelevant. Irrelevant transactions can be considered non-sequential transactions. However, when a transaction happens across multiple nodes and a relationship is established across nodes, that transactions becomes a related transaction. The established transaction relationship is the causal sequence. To understand the causal sequence, consider two transactions, one running on Node A and Node B and the other running on Node B and Node C. In this case, a relationship is established on Node B for the two transactions. The relationship on Node B maintains the transaction sequence.

A logical clock alone can ensure causal consistency and causal sequence. Then what is the biggest problem of a logical clock? In some extreme situations, a relationship will never be established between two nodes, leading to an increasing gap between the logical clocks for the two nodes. If we need to implement query or backup between the two nodes, a relationship must be established between them in a forcible way, causing an increasing gap between the logical clocks for the two nodes.
(5) Hybrid Logical Clock
Although the physical clock offset exists between machines, the offset can be very small if NTP verification or clock services like Google TrueTime are used. A hybrid clock in a distributed system consists of two parts: physical clocks in the upper half part and logical clocks in the lower half part. This hybrid clock is a hybrid logical clock (HLC). A hybrid logical clock combines the best of physical clocks and logical clocks. Because the offset between physical clocks is relatively small, we can compare the values of physical clocks. Because a certain offset is present between physical clocks, logical clocks can be used for calibration. The following figure shows an example of hybrid logical clocks. When a message is sent, the physical clock component of the hybrid logical clock is first compared with the current clock. If the current physical clock value is 4, when a new transaction occurs, the logical clock value adds 1 because the physical clock has not changed. If the physical clock changes from 4 to 4:01, advance the physical clock. If the physical clock does not get advanced, the addition should be made to the logical clock value. If the physical clock changes, the physical clock is advanced and the logical clock is set to zero.

(6) Differences Between HLC and Centralized Clock
In solutions based on a centralized clock, time is determined through transaction IDs so that all transactions can be sorted. In a distributed database, centralized nodes need to be eliminated. To do this, one method is to use logical clocks only. However, values between logical clocks cannot be compared. Another method is to use a hybrid logical clock, which defines a causal relationship between transactions. A hybrid logical clock does not have a centralized node and combines the local physical time with the logical time. Transactions generated locally do not have order preserved. However, if transactions happen across nodes, the causal relationship is sequential. The following figure shows the commit time of three transactions: T1 and T3 are two distributed transactions, and T2 is a standalone transaction. Because T1 is a distributed transaction and Process 1 on the database node is executed before Process 2, in the entire clock, the timestamp for Process 1 is smaller than that of Process 2 and that of Process 3. In this way, related transactions are properly sorted.

(7) Centralized Clock, Distributed Clock, and TrueTime
The following figure clearly shows the advantages of a centralized clock, which can ensure globally-consistent time. A clock in a distributed database does not encounter performance and HA bottlenecks that otherwise would occur in a centralized clock, because centralized timing service is not required for a clock in a distributed database. A clock in a distributed database provides two major capabilities. The first capability is horizontal scaling of computing and storage. The other is that the impact of single point of failure is reduced because workloads for a service in a distributed database are split onto different machines. The core database is split into hundreds of copies and failures on a single database only cause minimal impact on the availability of the entire system. One important reason why the combination of a distributed system and Internet Plus is currently so popular is that a distributed system can reduce the impact on service availability caused by a single point of failure. In addition to Internet companies, financial companies and institutions (for example, banks) also want to adopt distributed systems. For one thing, distributed systems can solve capacity and scalability problems. For another, distributed systems can solve the HA problem. Centralized clocks can cause single point of failures. Although distributed clocks eliminate single point of failures, they cannot implement sorting and true consistency with the periphery. Peripheral consistency means that sorting can be implemented between every pair of transactions. Distributed clocks can only sort correlated transactions to implement causal sequence. Google TrueTime can ensure globally-consistent time and simplify application development. However, the disadvantage is that TrueTime requires proprietary hardware. If the atomic clock in TrueTime is used for timing, a certain clock offset will occur, and this offset cannot be physically overcome. In Google Spanner papers, we know that each transaction has to wait for a period of time before it is submitted. This wait time is the clock offset.

2. Distributed Transaction Management
(1) Two-Phase Commit Protocol
Distributed transaction management ensures the atomicity and isolation of global reads/writes. A transaction occurring across two nodes may fail. If the transaction succeeds on one node but fails on the other node, the result is inconsistent, leading to the loss of the transaction atomicity. Another case is that the transaction is submitted successfully on both the nodes, but the commit time is not the same because the time on the two nodes themselves is not the same. If MVCC is used to read this transaction, only half of the transaction is visible. The other half part is invisible. This cannot ensure the atomicity of the transaction. A very mature technology is currently available to solve the transaction atomicity problem, that is, the two-phase commit protocol. The two-phase commit mechanism can be used to ensure that a distributed transaction either completely succeeds or completely fails. First, prepare transactions. If all prepared transactions are ready, commit them.
(2) Other Distributed Transaction Management Techniques
Common techniques for distributed transaction management fall into three types. The first type is two-phase commit, including the prepare phase and the commit phase. The second type is based on MVOCC. For example, FoundationDB is an open-source distributed database developed by Apple that uses MVOCC, which belongs in the type of OCC (optimistic concurrency control). While committing a transaction, the OCC method checks for conflicts, sets the conflict detection algorithm and weight algorithm based on conflicts and then decides whether to destroy or commit that transaction. Locks are applied beforehand and during update. Checks are performed to decide if any conflicts are present during the transaction submission. When the conflict is minor, the overall throughput is very high because no locking overhead is incurred. In case of severe conflicts, a large number of aborted transactions will be rolled back repeatedly. The third type is mainly for deterministic transactions, for example, Fauna.
A professor in the United States put forward the concept of deterministic transactions, established a company based on the deterministic transaction model and created a distributed database (Fauna). Deterministic transactions are complete transactions rather than interactive transactions. For example, all the transactions processed at the internet company Taobao are non-deterministic transactions. Non-deterministic transactions are operations like Begin Transaction and Select Transaction. Each operation is interactive, that is, the app needs to interact with databases. From the database perspective, a database can never predict the next statement. Transactions of this type are non-deterministic. All the logic of a deterministic transaction is written at a time and then sent to the database. When receiving that transaction, the database knows which tables this transaction involves, which records the transaction needs to read, and which operations are to be performed. From the database perspective, the transaction is completely deterministic. When received, deterministic transactions can be sorted in advance. If two transactions process the same records, the transactions are sorted. If they do not process the same records, they are sent out in parallel. This does not require locks and conflict detection during the submit phase later. However, this method requires that transactions are not interactive.
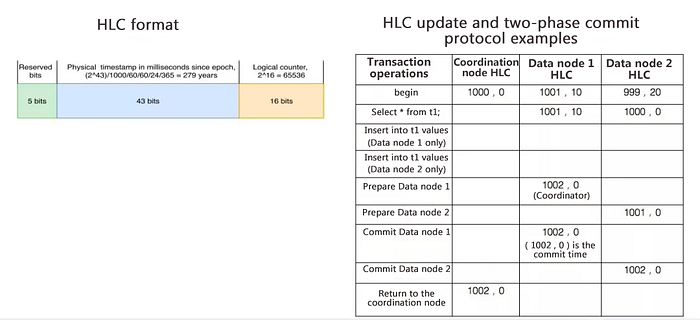
(3) HLC and Two-Phase Commit Protocol
The following figure shows the format of the HLC. Of the 64 bits, 5 bits is first reserved to ensure compatibility. In system design, a portion of bits are usually reserved in case of any problems. In the middle, 43 bits is set aside for physical clocks. The last 16 bits is used for logical clocks. If clocks are accurate to milliseconds, 43 bits for physical clocks means 279 years, during which the database runs incessantly. In general, this is unlikely. If physical clocks are accurate to days and the change per day is only one bit, then physical clocks are meaningless. The result of 16 bits is 65,536, which indicates that 65,536 transactions can be initiated in one millisecond. Generally, two clocks are consumed at the beginning and end, so this number needs to be divided by 2. That is to say, more than 30,000 transactions can be processed per millisecond, and one single node can process more than 30 million transactions per second.
(4) HLC Offset
An HLC is related to the transaction throughput, because it contains physical clocks and can display the clock offset between nodes. What if a clock offset really occurs? A simple formula is provided in the following figure. In case of no offset, a single node can theoretically have 30 million TPS, which is impossible from an engineering perspective. If two node clocks have an offset of 5 milliseconds, only logical clocks can be used to compensate for offsets of less than 5 milliseconds. Originally, more than 60,000 transactions can be processed in one millisecond, but now it takes 5 milliseconds. The transaction throughput is reduced by 6 million. Therefore, the clock offset can cause peak TPS to decrease dramatically. The following figure provides several solutions. One relatively simple solution is to set the maximum clock offset. If the maximum offset between two nodes in the entire data center or cluster exceeds 100 milliseconds, exception nodes need to be removed. Currently, many data centers use the NTP time service, so the probability of such a high offset is quite small. Another solution is to remain exception nodes and allow the logical clock to overflow to the physical clock so that the logical clock value becomes larger and more transactions can occur within the current clock.

About the Author
He Dengcheng (Nickname: Gui Duo), Senior Technical Expert at the Alibaba Cloud intelligent database department and a regular conferee at DTCC He has been devoted to the R&D of database kernels since 2005. He has worked for Shengtong Data, NetEase, and Alibaba successively. Currently he works at Alibaba and leads his team to build the new-generation distributed database — POLARDB-X.
