OceanBase Did Better than Any Other Database in the TPC-C Benchmark
11.11 Big Sale for Cloud. Get unbeatable offers with up to 90% off on cloud servers and up to a $300 rebate for all products! Click here to learn more.
This article was put together by the core research and development team of OceanBase:
Yang Zhenkun, founder of OceanBase
Cao Hui, technical expert of OceanBase
Chen Mengmeng, senior technical expert of OceanBase
Pan Yi, senior technical expert of OceanBase
Han Fusheng, senior technical expert of OceanBase
Zhao Yuzong, advanced technical expert of OceanBase

Developed by the Transaction Processing Performance Council (TPC), TPC-C is an online transactional processing (OLTP) benchmark that is made specifically for testing transactions such as order creation and order payment in commodity sales. It is an authoritative, industry-standard benchmark for the online transactional processing system of a database.
OceanBase, Ant Financial’s distributed relational database, got the best results out of any database in the TPC-C benchmark, which, naturally, attracted a lot of attention. In this article, the core research and development team of OceanBase present their understanding of this benchmark and tell how OceanBase went a step beyond all the other databases tested.
How Did OceanBase Do So Well on the TPC-C Benchmark?
All database kernel developers want to take on the challenge of the TPC-C benchmark. However, it is never easy to meet all of the challenges presented in complex benchmarks like TPC-C, and this also happened to be the very first time that OceanBase took on the TPC-C benchmark. So, how did the OceanBase team do it? Well, to beat the test, the OceanBase research and development team prepared for more than a year.
Test Preparations
The TPC-C benchmark must be audited and supervised by officially certified auditors. Around the world, there are only three auditors who are officially certified by the TPC, two of whom were invited to audit the OceanBase benchmark test. The TPC attached a lot of importance to the OceanBase’s test.
How the Test Worked
At present, there aren’t any testing tools that can 100% simulate the TPC-C benchmark right out of the box. For example, BenchmarkSQL is one that comes close, but still doesn’t fully meet the mark. For those who don’t know, BenchmarkSQL is an easy-to-use Java Database Connectivity (JDBC) benchmark that simulates the TPC-C standard benchmark for OLTP. It is the most widely used tool of its kind, often used as a benchmark for proof-of-concept environments. However, it is only a test for stress testing that can more or less simulate the TPC-C benchmark, but it cannot fully simulate all of the requirements of the benchmark even when it comes to some basic data import fields. Also, BenchmarkSQL cannot globally generate a large number of strings at random, and it doesn’t have the basic configurations typically required for standard stress testing benchmarks such as key-in and think time. Because of this, a small amount of data can result in a large number for the transactions per minute, or more specifically a large tpmC value. Among all of its shortcomings, though, probably the worst of all is that BenchmarkSQL has simplified the test model into a direct connection between the test tool and the database being tested, which naturally also fails the standards of the TPC-C benchmark.
As defined by the TPC-C benchmark, a test system can be divided into the remote terminal emulator (RTE) and system under test (SUT). In fact, the SUT can be further divided into the web application server (WAS) and the database server from the role perspective.
A database server is the database service provided by each vendor under testing. The RTE plays the role of a user terminal in the test model, which completes tasks such as transaction triggering and response time collection. The TPC-C benchmark requires that each user terminal maintain a persistent connection to the database server. However, database servers cannot support such number of connections in massive warehouses, for example, so, in such cases, the WAS bridges the RTE and the database server. According to the TPC-C benchmark guidelines, a connection pool can be used to manage all requests when the connection pool is transparent to applications.
Among the three roles, the WAS and the database server must be commercially available and provide payment services. OceanBase used OpenResty as its WAS provider. Generally, the RTE is implemented by each vendor under the test according to the benchmark. However, all implementation code must undergo strict auditing by the auditors. OceanBase implemented a complete set of RTEs that were fully compliant and could be deployed in a large test system. During the actual TPC-C benchmark test, the capabilities of the database server are tested, and RTEs need to be able to consume a lot of resources and withstanding a high amount of stress. In this test, we received the tpmC value of 60,880,000 and ran 960 RTEs on 64 64-core 128-GB cloud servers to simulate total 47,942,400 user terminals. Last, we audited and verified the consistency and durability of the RTE statistics.
Although RTEs were only used as clients during a benchmark test, many details might lead to a test failure. For example, the response time of all transactions increased by 100 ms due to the introduction of web terminal simulators, which may not be noticeable at first, and the output display was delayed for 100 ms due to the use of user terminal simulators.
Test Planning
The TPC-C test has never been simple. There is no mandatory software or hardware configurations for the benchmark test. Rather, associated with the benchmark test are just a bunch of auditing restrictions and standards. Database vendors can obtain good performance or cost-effectiveness in the test by maximizing the feature sets of their databases. However, this of course, though, poses a great challenge to vendors during the testing phase, as they will need to appropriately plan their existing resources to be listed in the TPC-C ranking list.
- Hardware selection: In addition to the database server model, the RTE and WAS models also need to be determined. A large number of tests and optimizations are required to find the appropriate resource configuration of the server for each role while also ensuring cost-effectiveness. During OceanBase’s benchmark test, only cloud-based resources were used. This offered the biggest benefit for this test because we did not need to concern ourselves with the specifics of the underlying infrastructure, including the data centers, cabinets, and cabling. Instead, we only needed to rapidly adjust the specifications to find the target models.
- Parameter selection: It is not easy to determine appropriate configuration parameters. For instance, two typical parameters are the total number of warehouses we need to run, and the number of warehouses that are borne by each database server. To simulate a business scenario that is as practical as possible, the TPC-C benchmark sets different think times and keying times for each transaction to ensure that the data in a warehouse can provide a maximum tpmC value of 12.86. Therefore, a database vendor must load more warehouses to ensure higher performance. However, past experience shows that 80% of the storage space on a single server must be reserved for 60 days’ worth of incremental storage. In the distributed database schema, to make full use of each database server and the local storage and maximize the utilization of the CPU, memory, I/O capability, and storage space of each server, we had made adjustments and optimizations for nearly one month.
Performance Stress Tests
For the performance stress test, which happened to attract the most attention, the TPC-C benchmark defined the following states:
- Ramp-up. According to the TPC-C benchmark, each database is allowed to warm up for a certain period of time to be a steady state when the test is performed. However, all the configurations at the ramp-up stage must be consistent with the configurations in the final report.
- Steady. When the atomicity, consistency, isolation, and durability (ACID) as well as the serializable isolation are guaranteed, the database can run at the steady state for more than eight hours, with the tpmC value specified in the final report without manual intervention. In addition, the database completes a checkpoint every half an hour.
- Measurement interval. According to the TPC-C benchmark, the database needs to run at the steady state for eight hours, but only needs to run for more than two hours at the performance collection state. At this stage, the total tpmC fluctuation must not exceed 2%, and the database must complete at least four checkpoints.
Previously, the general process for performing the performance stress test on a database was as follows: Allow the database to warm up for a certain time so that it can reach the steady state. After the database enters the steady state for a certain period of time and completes a checkpoint, the performance collection stage begins, which typically lasts for two hours.
However, the most rigorous process in the TPC-C test up to this point in the test is the part that tests OceanBase’s computing performance. For this part, OceanBase was first warmed up for 10 minutes. Then, following this, it was run at the steady state for 25 minutes with a tpmC value of 60,880,000. Finally, OceanBase ran for eight hours at the collection stage of the performance stress test. The total test duration exceeded 8.5 hours, and the occurrence of the largest performance fluctuation during this period was less than 0.5%. This final result surprised the auditors.
Before and after the performance test, the auditors also need to check the random distribution of data and transactions, which involves a large number of full-table scans and SQL statistical collections. The most heavyweight SQL statement needs to access the order_line table with more than one trillion rows of items, which can be regarded as a type of TPC-H benchmark test inside of the TPC-C benchmark test. In the field audit, we also encountered many timeout errors during SQL statement execution when these SQL statements were run for the first time. Subsequently, we used the latest concurrent execution framework in OceanBase 2.2 and successfully completed the execution of these heavyweight SQL statements within a relatively short time. A really general relational database has no weaknesses. In this sense, OceanBase still needs to learn from Oracle.
Atomicity, Consistency, Isolation, and Durability (ACID)
- In the atomicity (A) test, we verified the database’s support for the atomicity by committing and rolling back payment transactions. Similar to the isolation (I) test, we conducted the atomicity (A) test on OceanBase twice for distributed and local transactions, respectively.
- The consistency © test in the TPC-C benchmark consists of 12 cases, four of which must be tested. Actually, each case can be seen as a heavyweight and complex SQL statement. For a distributed database, it is important to ensure the global consistency all the time.
- In the I test, the TPC-C benchmark requires that the five transactions, except StockLevel in the TPC-C model, reach the highest isolation at the serializable level, and that nine cases need to be constructed to verify the isolation. For a distributed database, it is not easy to meet this requirement. Fortunately, OceanBase versions 2.0 and later support global timestamps. Therefore, as required by the auditors, we conducted the isolation (I) test twice in the fully local and fully distributed modes respectively. It was also the first time that the isolation (I) test had been conducted twice for a database vendor in the TPC-C test and that the I test consisted of 18 cases. In the coming future, the definition of the TPC-C benchmark may be updated for distributed databases due to the test on OceanBase.
- In the durability (D) test, OceanBase had a great natural advantage over traditional databases. In OceanBase, each warehouse has two data replicas and three log replicas, which are synchronized over the Paxos protocol. This ensures that the recovery time objective (RTO) is within seconds when the recovery point objective (RPO) is 0.
In the D test, the strictest test item is the permanent failure of certain storage media. The most rigorous test scenario was used for OceanBase. With the largest tpmC value of 60,000,000 that exceeded the requirement of the TPC-C benchmark, we forcibly destroyed a cloud server node. OceanBase restored the tpmC value to 60,000,000 within two minutes and continued running until the test ended. The performance shown during this test had far exceeded the requirements of the TPC-C benchmark. In comparison, other traditional databases often use Redundant Arrays of Independent Disks (RAIDs) to restore data in case of a failure of storage media with logs in the D test. OceanBase was the first database vendor that completed all the test items of the D test by only using the recovery mechanism of the database but not a RAID.
In the D test, we destroyed two server nodes consecutively. We first destroyed a data node. After OceanBase restored the tpmC value and ran at the steady state for five minutes, we destroyed the rootserver leader node. Then, OceanBase rapidly restored the tpmC value again.
Some SQL Optimizations for the TPC-C Benchmark
Anyone who knows about TPC-C also knows that TPC-C is a typical Online Transaction Processing (OLTP) scenario test. It tests the transaction processing capability of a database under high concurrency pressure. The final performance metrics are tpmC and the average system cost per tpmC. The tpmC value indicates the number of new order transactions processed by the system every minute in the TPC-C model. In an OLTP scenario, the response time for each request is extremely short. Therefore, each database vendor needs to do everything possible to minimize the time of each operation during the TPC-C test. Therefore, it is not an exaggeration to say that, in the TPC-C test, certain key operations are often refined to the CPU command level.
First of all, we will discuss the five transaction models in the TPC-C benchmark, which are order creation, order payment, order query, order delivery, and inventory query. These five transactions occur at a certain ratio, and the number of order creation transactions that are executed per minute will be finally tested. As we know, each database transaction is composed of several SQL statements associated with a certain logical structure. All of these SQL statements either succeed or fail in a transaction, something which is referred to as “atomicity” in the database, which corresponds to letter “A” in the “ACID” string. But, how much time does a transaction consume during a TPC-C benchmark test? This is clearly specified in the report, and is only dozens of milliseconds. Considering that a transaction is composed of several SQL statements, the average time consumed by each SQL statement is less than one millisecond.
In the client-server (C/S) model, a SQL statement goes through a complete process from input on a client to transmission on a network, optimization, execution, and returning the results to the client. However, an SQL statement may be executed simply to update a field, which requires a short time. When considering the entire process, lots of time is spent on interaction with the client, which results in wasted resources and increased time consumption. But how can this problem be solved? The solution is to use a stored procedure.
Stored Procedure
A stored procedure is a procedure-oriented programming language that a database provides for users. By using this language, users can encapsulate the logic of an application as a callable procedure and store the procedure into the database, which can be called later at any time. In this way, users can complete the work in one interaction with the database, instead of multiple interactions. This saves the transmission and waiting time on the network. If the average network overhead of a transaction is 30%, 30% of the CPU usage is for receiving, transmitting, and parsing transactions on the network. Therefore, a high system processing capability can be converted from 30% of the CPU usage that can be saved in the tpmC test at the scale of 60 million. Using a stored procedure also helps reduce the response time of transactions, which in turn shortens the critical section of transaction locks in the database kernel, indirectly improves the CPU utilization of the system, and increases the overall throughput. A stored procedure is also helpful in reducing the waiting time of applications.
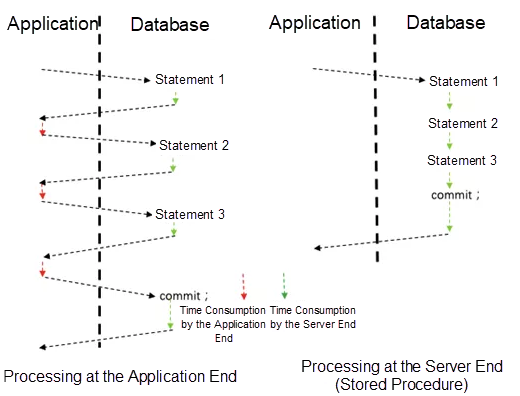
Figure 1. Execution comparison between the traditional C/S model and a model in which a stored procedure is used.
In TPC-C, a stored procedure is crucial for improving the execution efficiency of the entire system. OceanBase version 2.2 supports stored procedures at all stages, and has also optimized the execution efficiency of the stored procedures.
Compilation and Execution
A stored procedure is an advanced language that orients to procedures and can be executed only after it is converted to machine code. In general, there are two approaches to the execution of a stored procedure, which are “compilation” and “interpretation”. As you probably know, a “compiled” stored procedure usually exhibits much better performance than the “interpreted” one. This is thanks to its highly optimized executable code. OceanBase has implemented a compiler that supports stored procedures by using the Low Level Virtual Machine (LLVM) compiler framework, which has been optimized in the recent two years. This compiler can translate stored procedures into efficient binary executable code by means of just-in-time compilation, which improves the execution efficiency by an order of magnitude. In addition, the LLVM compiler framework can translate stored procedures into intermediate code that is machine-independent. Therefore, the stored procedures can be compiled and executed across platforms. In addition, the built-in optimized procedure of the LLVM ensures that correct and efficient executable code can be obtained on different hardware platforms.
Array Binding
Another feature that plays an important role in the TPC-C test is the capability of processing Data Manipulation Language (DML) statements in batches. In Oracle, this feature is also referred to as “Array Binding”. In a database, a SQL statement is often executed at two stages, which are the plan generation and execution stages. Although we implemented high-speed caching for the execution plans of SQL statements, it is still time consuming to find an appropriate execution plan during execution. So, is it possible to save this time? When a group of SQL statements have the same execution plan and different execution parameters, we can compile the execution of these SQL statements into batch processing by using a special syntax during the stored procedure, which is referred to as array binding. In this case, plan generation only needs to be performed once.
During array binding, the database first finds the plan to be used, and then executes the plan. After each execution, the database performs array binding again. This is similar to a FOR loop in the C language. New values are assigned repeatedly, but no new data structure is defined. The array binding feature is controlled by users and can be triggered by the FORALL keyword during the execution of the stored procedure. In the TPC-C test, we used the array binding feature for multiple times to improve the processing capability of the system, which achieved significant performance.
Prepared Statement and Execution Plan Cache
Prepared Statement is a binary request interaction protocol, which can greatly reduce the interaction cost of the system. In OceanBase, Prepared Statement can be used between user programs and the database. Also, it can also be used when the stored procedure engine calls the SQL engine to execute SQL statements. After the system prepares SQL statements and obtains a unique ID in a stored procedure, only this ID and corresponding parameters need to be input in each subsequent execution. The system can find the corresponding stored procedure or SQL execution plan in the high-speed cache, and then start execution. Compared with the interaction based on SQL text, this interaction process can save the high CPU overhead for parsing request text.
OceanBase implements a high-speed cache to store the executable code and SQL execution plans of stored procedures. The system can rapidly obtain the execution objects for stored procedures and SQL statements with different parameters from this high-speed cache, generally within dozens of microseconds, which effectively avoids delay being in the milliseconds and CPU consumption caused by recompilation.
Updatable View
In OLTP scenarios, there are many examples where performance can be improved by reducing interactions between applications and databases. The updatable view is one of these examples. Common database views are read-only. By defining a view, users can define the data they are interested in and the APIs for accessing the view. However, a view can also be used as the entry to an update operation. For example, in the scenario of creating a new order in TPC-C, an application needs to obtain commodity information, update the inventory, and obtain the updated values. Generally, two SQL statements are used to implement this process.
select i_price,i_name, i_data from item where i_id = ?;
UPDATE stock
SET s_order_cnt = s_order_cnt + 1,
s_ytd = s_ytd + ?,
s_remote_cnt = s_remote_cnt + ?,
s_quantity = (CASE WHEN s_quantity< ? + 10 THEN s_quantity + 91 ELSE s_quantity END) - ?
WHERE s_i_id = ?
AND s_w_id = ?
RETURNING s_quantity, s_dist_01,
CASE WHEN i_data NOT LIKE'%ORIGINAL%' THEN 'G' ELSE (CASE WHEN s_data NOT LIKE '%ORIGINAL%' THEN 'G'ELSE 'B' END) END
BULK COLLECT INTO ...;However, in the case that an updatable view is created, then the following can be done.
CREATE VIEW stock_item AS
SELECT i_price, i_name, i_data, s_i_id,s_w_id, s_order_cnt, s_ytd, s_remote_cnt, s_quantity, s_data, s_dist_01
FROM stock s, item i WHERE s.s_i_id =i.i_id;Specifically, an SQL statement can be used to update the inventory and obtain the commodity and inventory information.
UPDATE stock_item
SET s_order_cnt = s_order_cnt + 1,
s_ytd = s_ytd + ?,
s_remote_cnt = s_remote_cnt + ?,
s_quantity = (CASE WHEN s_quantity< ? + 10 THEN s_quantity + 91 ELSE s_quantity END) - ?
WHERE s_i_id = ?
AND s_w_id = ?
RETURNING i_price, i_name, s_quantity,s_dist_01,
CASE WHEN i_data NOT LIKE'%ORIGINAL%' THEN 'G' ELSE (CASE WHEN s_data NOT LIKE '%ORIGINAL%' THEN 'G'ELSE 'B' END) END
BULK COLLECT INTO ...;This eliminates the need for an additional SQL statement and makes the update logic more intuitive. Users can use updatable views as common views, but cannot define all views as updatable views. For example, views that contain DISTINCT and GROUP BY cannot be updated because the semantics do not specify the rows to be updated. As for the “stock_item” view, which is essentially a join between the “stock” table and the “item” table, it is guaranteed by the uniqueness of “item.i_id” that each row from the base table “stock” corresponds to at most one row in “stock_item”, an attribute also known as “key-preserved” in some literature.
Note: The TPC-C benchmark does not allow for materialized views. However, an updatable view does not change the storage schema of the data tables at the underlying layer, and therefore meets the TPC-C benchmark.
The TPC-C benchmark requires that the design reflect the “actual” running of an OLTP system. Many of our optimizations are applicable to various applications. For example, in a highly concurrent OLTP system, most SQL requests consume a short time. If a pure C/S interaction model is used, frequent interactions between applications and the database consume lots of system time. However, stored procedures can reduce the time consumed by these interactions and enhance the network jitters immunity of the system. This core capability is indispensable for a distributed OLTP database.
In the TPC-C test, OceanBase version 2.0 started to be compatible with Oracle, in which all stored procedures and SQL statements used data types and syntax that were compatible with Oracle. In this way, we could constantly optimize the database and develop the database in the general and formal direction.
Challenges Placed on Database Transaction Engines during TPC-C Benchmark Testing
In the TPC-C test, OceanBase was quite different from other listed databases such as Oracle and DB2 in terms of hardware. OceanBase used 207 Alibaba Cloud Elastic Compute Service (ECS) servers of ecs.i2.16xlarge, 204 of which were used as data nodes and three of which were used as root nodes. You can easily purchase these nodes on the official website of Alibaba Cloud. If you look through the TPC-C test reports of Oracle and DB2, you will find that these databases used proprietary storage devices. For example, Oracle was the former record keeper in the test of 2010, and Oracle used 97 proprietary storage devices of COMSTAR, 28 of which were used to store Redo logs of the database.
Different hardware imposes different challenges on the software architecture. Proprietary storage devices provide internal reliability by using redundant hardware. When database software uses these storage devices, no data loss occurs due to these pre-existent properties. However, proprietary storage devices are expensive, which leads to high costs.
OceanBase uses common ECS servers to provide database services and only uses the local hard disks delivered with the ECS servers for data storage, which is the most common hardware usage condition. However, individual ECS servers are less reliable than proprietary storage devices, which brings huge challenges on the software architecture. The transaction engine of OceanBase was also challenged because OceanBase achieved the ACID characteristics on common ECS servers.
The TPC-C benchmark has complete and strict requirements for the ACID characteristics of transactions. The following section introduces how OceanBase has implemented the ACID characteristics of transactions.
Ensure the Durability by Synchronizing Paxos Logs
OceanBase ensures the durability of transactions by relying on the durability of Redo logs. All Redo logs are forcibly synchronized to another two database servers in real time. Therefore, three database servers are used to ensure the durability of Redo logs on hard disks, including the database server that generates Redo logs.
OceanBase uses Paxos to coordinate the durability of Redo logs on the three database servers. Paxos is a consistency synchronization protocol that uses an algorithm that considers success if more than half (the majority) members succeed. When three replicas are available, two successful replicas will be considered as the majority. After Redo logs are synchronized between database servers to ensure the durability, the transactions can be committed. Generally, the third database server can also complete the synchronization of Redo logs to ensure the durability immediately. However, even if the third database server encounters an exception, it does not affect the committing of the transactions. The system will automatically synchronize the missed Redo logs with this database server after it recovers. If the third database server encounters a permanent fault, the system distributes the Redo logs to be originally synchronized by the fault database server to other database servers in the cluster. These database servers will automatically supplement the missed Redo logs and write the latest Redo logs.
The Paxos protocol implements the best balance between data durability and database service availability. When three replicas are used, any unavailable replica does not affect subsequent writes because the other two replicas can provide data and support subsequent writes.
Therefore, OceanBase can also improve the continuous service capability of the database while ensuring the durability of transactions. When the TPC auditors audited the durability of OceanBase on the field, they selected a random server and forcibly powered off the server under constant pressure from the client. From the audit results, they found that the database did not lose any data and could continue to provide services without manual intervention. This impressed the auditors, who highly praised OceanBase.
Ensuring Atomicity by Using the Two-phase Commit Protocol
Among the five transactions in the TPC-C test model, order creation and order payment are complex and involve a lot of data modification. The TPC-C benchmark has forcible requirements for the atomicity of transactions. It requires that all modifications to tables, such as the warehouse, order, and user tables inside a transaction, take effect atomically, and half success is not allowed.
OceanBase distributes data to multiple servers by warehouse ID (Warehouse_ID). If all transactions occur within the same warehouse, all transaction modifications only involve the data of one server, and all transactions will be committed on this server regardless of the data volume. This scenario demonstrates the ideal linear scalability. However, this is different from the actual business scenario. Actually, most actual businesses require data interactions in different dimensions. The TPC-C benchmark has also considered this aspect and put forward requirements for random rules of transaction data. It requires that the finally generated transactions include 10% of “order creation” transactions and 15% of “order payment” transactions that involve operations of two or more warehouses. In OceanBase, transactions across servers will be generated, whose atomicity must be ensured by the two-phase commit protocol.
OceanBase automatically traces the operation data of all SQL statements in a transaction, and automatically determines the participants of the two-phase committing based on the actual data modification location. Before a transaction is committed, OceanBase automatically selects the first participant as the coordinator. The coordinator sends a Prepare message to all participants. Each participant then needs to write their own Redo and Prepare logs, which means that each participant completes Paxos synchronization on their own. After the coordinator confirms that all the participants have completed the synchronization of the Redo and Prepare logs, the coordinator sends a Commit message to all the participants and waits until all participants complete the committing. OceanBase automatically completes the entire protocol during the committing of transactions, which is fully transparent to users. OceanBase automatically selects a coordinator for each two-phase commit transaction, and any server in the system can serve as a coordinator. Therefore, OceanBase can linearly scale out the transaction processing capability.
Ensuring the Isolation of Transactions by Controlling Multi-version Concurrency
The TPC-C benchmark requires that the order creation, order query, order delivery, and order payment transactions be isolated at the serialized level. OceanBase uses the concurrency control mechanism based on multiple versions. While committing a transaction, OceanBase requests a committing timestamp for the transaction. Modifications within a transaction will be written into the storage engine to produce a new version, and the previous version will not be affected. When a transaction starts, OceanBase obtains a read timestamp. Within this transaction, only data that is committed based on the timestamp can be read. Therefore, no dirty data, non-repeatable read, and phantom read will occur in transaction reading. In addition, each modified data row in a transaction has a row lock, which prevents concurrent modification of the same row.
OceanBase has three replicas of the global timestamp generator, which can be independently deployed on three servers. In addition, one replica can be deployed on the root node to share resources with the root node, as it was deployed in the TPC-C test. The three replicas of the global timestamp are deployed in a high-availability architecture. Reading any timestamp will be confirmed on at least two of the three servers. Therefore, upon the failure of any server, reading the timestamp is not affected.
According to the TPC-C benchmark, OceanBase prepared nine different scenarios for testing the isolation of transactions, including the read-and-read scenario and the read-and-write conflict scenario. Finally, OceanBase successfully passed the audit by the auditors.
Ensure the Consistency
With the preceding transaction capabilities, OceanBase can well ensure the consistency of various data. The TPC-C benchmark provided 12 scenarios to verify the consistency of data in the database before and after various tests. A huge volume of data was involved in the test on OceanBase, and the consistency check SQL statements needed to check massive data. Therefore, the challenge of the consistency check lay in the running efficiency of the consistency check SQL statements. Based on the concurrent query capability of OceanBase, by using the computing resources in the entire cluster, the consistency check SQL statements successfully completed the consistency check with the running time reduced by several orders of magnitude.
Duplicate Table
The TPC-C test model has an item table that contains information about all the products that are sold by a simulated sales company, including product names and prices. When an order creation transaction is executed, the transaction requests the data in the item table to determine the order price. If the data of this table is only stored on one server, the order creation transactions generated on all servers will send requests to the server that stores the item table. In this case, the server that stores the item table becomes a bottleneck. OceanBase supports the duplicate table feature. After the item table is configured as a duplicate table, OceanBase automatically duplicates the data of the item table to all servers in the cluster.
The TPC-C benchmark does not limit the number of data replicas, but requires that the ACID characteristics of the transactions be guaranteed regardless of the data formats. OceanBase uses a special broadcast protocol to guarantee the ACID characteristics of the duplicate table in all replicas. When the duplicate table is modified, all replicas will also be modified. In addition, when a server fails, the logic of the duplicate table automatically removes the invalid replica so that there is no unnecessary waiting time caused by the server failure during data modification. Duplicate tables can be used in many business scenarios, such as dictionary tables that store key information in various businesses, and tables that store exchange rate information in financial businesses.
4. Storage Optimization for TPC-C Benchmark Testing
The TPC-C benchmark requires that the performance (tpmC) of the database under testing be proportional to the data volume. The basic data unit of TPC-C is a warehouse, and the data volume of each warehouse is usually around 70 MB, which depends on the specific implementation. According to the TPC-C benchmark, the maximum value of tpmC for each warehouse is 12.86, assuming that the response time of the database is 0.
Assume that the tpmC value of a system is 1.5 million, which corresponds to 120,000 warehouses. If the data volume of a warehouse is 70 MB, the total data volume will be 8.4 TB. Some vendors use a modified TPC-C test that does not meet audit requirements. This test does not limit the maximum value of tpmC for a single warehouse. In addition, these vendors test the performance of loading hundreds or thousands of warehouses to the memory, which is meaningless and does not help pass the audit. In an actual TPC-C test, the test on storage consumption accounts for a great portion. OceanBase is the first database to have ranked first in the TPC-C test by using the Shared Nothing architecture and the log-structure merge-tree (LSM tree) storage engine architecture. The storage architecture of OceanBase has the following key features:
- To ensure reliability, OceanBase stores data in two replicas and logs in three replicas. In the TPC-C test, traditional centralized databases only stored data in one replica.
- In the TPC-C test, OceanBase used two data replicas and Alibaba Cloud ecs.i2.16xlarge servers that were the same as those in production systems. Therefore, the storage capacity of solid-state drives (SSDs) became the bottleneck. OceanBase resolved this problem by using online compression, which further increased the utilization rate of the CPU. Accordingly, data was stored in one replica in the test for centralized databases and data compression may not be opened.
- The LSM engine of OceanBase needs to regularly perform compaction at the background, but the TPC-C benchmark requires that the database run for at least eight hours with jitters less than 2% in two hours. Therefore, OceanBase needs to resolve the jitters caused by the background operations of the LSM engine.
Two Data Replicas
To ensure reliability and avoid data loss (RPO=0), two solutions are available: fault tolerance at the hardware layer and fault tolerance at the software layer. OceanBase chooses fault tolerance at the software layer, which requires lower costs than the other solution. However, fault tolerance requires that data is stored in multiple replicas. OceanBase uses the Paxos protocol to ensure high data consistency in the case of single server failure. In the Paxos protocol, writing a piece of data is considered successful only after the data is synchronized to the majority — more than half of the members. Therefore, the number of replicas is always odd. For cost considerations, the most common deployment consists of three replicas.
The primary issue caused by three data replicas is the increased storage cost. Most traditional business databases used disk arrays in the TPC-C test, and the TPC-C benchmark has no requirements for disaster recovery. Therefore, it is not allowed to use storage space that is three times the storage space used by traditional databases in the TPC-C test.
Based on this fact, we only use the Paxos protocol to synchronize logs. Logs will be written into three replicas, but data will only be written in two replicas for disaster recovery in case of single server failure. When a server fails and invalidates one replica, the other replica can supplement the missed data by using logs and continue to provide external access.
Compared with data, logs consume smaller storage space. We defined three types of replicas to separate data from logs: The F replica stores data, synchronizes logs, and provides external reads and writes. The D replica stores data, synchronizes logs, but does not provide external reads and writes. The L replica only synchronizes logs, but does not store data. When the F replica becomes faulty, the D replica takes over the F replica to provide external reads and writes after supplementing the missed data. In the TPC-C test, we deployed the F, D, and L replicas, which used the storage space required by two data replicas. Both the D and L replicas need to play back logs, and the D replica also needs to synchronize data. All these operations consume the network and CPU resources.
Online Compression
In the Shared Nothing architecture, OceanBase needs at least two data replicas to meet the requirement for disaster recovery. This means that OceanBase needs a storage space that is twice the storage space for traditional databases.
To resolve this problem, OceanBase performed online compression for the data in the TPC-C test. In Oracle, the storage capacity of a warehouse is about 70 MB. However, in OceanBase, the storage capacity of a compressed warehouse is only about 50 MB, which is a significant reduction in storage space. According to the TPC-C benchmark, a database must provide disk space for storing the data of 60 days. However, OceanBase must store data in two replicas, which is equivalent to the data of 120 days. Although this provides higher reliability, the higher storage cost also leads to a higher total price.
OceanBase uses 204 ECS cs.i2.16xlarge servers to store data. The server type is the same as that for actual online business applications. The size of the log disk on each server is 1 TB, and the data disk size is nearly 13 TB. We calculated the storage space required by the two compressed data replicas in 60 days, and found that the data disk of each server was almost exhausted. According to the resource cost consumed by the servers, a balance had been reached. After the single-server performance in tpmC of OceanBase is further improved, the disk capacity will be a bottleneck. The OceanBase LSM engine is append-only, which does not allow for random modification and supports online compression. Both for the TPC-C test and core OLTP production systems such as Alipay’s transaction payment system, OceanBase will enable online compression to exchange storage space with the CPU capability.
Smooth Storage Performance
According to the TPC-C benchmark, the performance curve that is obtained during the stress test must be smooth and the portion of fluctuations on the curve cannot exceed 2%. This imposes a big challenge and is tough for traditional databases, because all background tasks must be accurately controlled and no foreground request is blocked or accumulated due to excessive resource usage by a background task. However, this is even tougher for OceanBase because the storage engine of OceanBase is based on the LSM tree that performs compaction regularly. Compaction is a heavyweight background operation that consumes many CPU and disk I/O resources. This affects the foreground queries and writes by users. Against this, we made some optimizations to relieve the impact of background tasks on the performance. According to the final test result, the portion of jitters on the performance curve was less than 0.5% during the eight-hour stress test.
Layered Dump
In LSM tree, data is first written to the MemTable in the memory. If necessary, the data in the MemTable will be merged with the data in the SSTables on the disk to release memory space. This process is called compaction. In many storage systems based on LSM trees, all SSTables are often divided into multiple levels to improve the write performance. When the number or size of the SSTables at a level reaches a threshold, data is merged into the SSTables at the next level. The multi-layer SSTables improve the write performance, but the large number of SSTables slows down queries. OceanBase also uses layering with a compaction policy that is more flexible to ensure that the total number of SSTables is small and the read and write performance is better balanced.
Resource Isolation
Background tasks such as compaction consume many server resources. To reduce the impact of background tasks on queries and writes by users, we separate resources for the foreground and background tasks in terms of CPU, memory, disk I/O, and network I/O. In terms of CPU, we divide background tasks and user requests into different thread pools and isolate the thread pools according to their affinity to the CPU. In terms of memory, we manage foreground and background requests in different memory spaces. In terms of disk I/O, we control the input/output operations per second (IOPS) of I/O requests for background tasks and use the deadline algorithm for throttling. In terms of network I/O, we divide the remote procedure calls (RPCs) of background tasks and user requests into different queues, and perform throttling for the bandwidth used by the RPCs of background tasks.
CPU Usage by the Storage Module
The TPC-C benchmark concerns about the overall tpmC, and many people also concern about the tpmC value of a single core. However, this metric makes sense only in the same architecture. In terms of CPU usage by the storage module, note the following:
- In a centralized architecture, the database needs to use the CPU, and proprietary storage devices also need to use the CPU. For example, Oracle ranked second in the TPC-C tests. In the test on the tpmC value of more than 30 million, the database used 108 SPARC T3 processors and involved 1,728 physical cores and 13,824 execution threads. In addition, the storage module used an Intel-core server as the controller with additional 97 servers, 194 Intel X5670 CPUs, and 2,328 physical cores.
- A centralized database uses hardware with high reliability, and therefore only needs one replica for storage. However, OceanBase implements fault tolerance by using software. Although the hardware cost is low, maintaining two data replicas and three log replicas uses lots of CPU resources.
- OceanBase enabled online compression in the TPC-C test and production systems, which further increased the CPU usage.
Therefore, it is not rational to simply compare the CPU cores used by OceanBase and Oracle. Instead, the CPU cores shared by storage devices, and the CPU overhead caused by multi-replica storage and online compression of OceanBase must also be taken into account. The scheme recommended by TPC-C does not emphasize to specific software and hardware architecture, but focuses on the total hardware cost. In the test on OceanBase, the hardware cost accounted for about 18% of the total cost. Therefore, the cost-effectiveness of OceanBase is much higher than centralized databases when hardware is the only consideration.
Future Development
OceanBase offers the benefits of a distributed architecture, low hardware costs, high availability, and linear scalability. However, the single-server performance of OceanBase is far lower than that of Oracle and DB2. In the future, we will strive to optimize the performance of single-server storage. In addition, OceanBase is designed to support both OLTP and online analytical processing (OLAP) businesses by using the same engine. Currently, OceanBase falls behind Oracle in terms of OLAP capability. In the future, we will enhance the storage module to support the processing of heavyweight queries, shift OLAP operators down to the storage layer, and even directly perform OLAP operations on compressed data.
