Struggling with Poor Responsiveness? Unlock the Power of Caching

By Kehuai
1) Common Concepts
Before implementing caching, it’s critical to understand the following terms commonly used in the caching field:
1) Cache Hit: It indicates that data is obtained from the cache without having to retrieve it from the source.
2) Cache Miss: When the cache is not hit, data is retrieved from the source. If free space is available in the cache, the specific data is cached.
3) Storage Costs: In the case of a cache miss, data retrieved from the source is stored. The time and space that are required to store the data in the storage space are referred to as the storage costs.
4) Cache Invalidation: When source data changes, the currently cached data becomes invalid.
5) Cache Pollution: It occurs when infrequently accessed data is cached, taking up space that could be used for frequently accessed data.
6) Replacement Policies: When the cache becomes full and it is necessary to remove existing data to cache new data, a replacement policy determines which data must be removed. Common replacement policies include:
- Least-Recently-Used (LRU)
- Least-Frequently-Used (LFU)
- SIZE
- First in First Out (FIFO)
Faced with limited storage space, replacement policies aim to cache the most frequently accessed data as far as possible and reduce cache pollution to improve the cache hit ratio and overall cache efficiency. Therefore, it’s essential to find the optimal replacement policy based on historical data access conditions and a good estimate of future access conditions.

2) Analysis — Cache Access Scenarios
When a cache is used, requests generally attempt to access cached data first. If the required data is not cached, the request is sourced back to the database and the obtained data is written to the cache. If the required data is found in the cache, the system returns the data directly. From an overall perspective, the cache layer is the first stage in the data access process. This means that, like databases, it is prone to system faults during high-concurrency access periods. Therefore, carefully analyze the cache layer.
Let’s take a look at the three common cache access problems.
2.1) Cache Penetration
Symptoms: Each request passes through the cache layer and is directly returned to the database, imposing massive pressure on the database or even causing the database to crash.
Cause: Data access requests are first sent to the cache. If the data does not exist in the cache, the database is queried. However, if the required data is not found in the database, it cannot be written to the cache. In this way, requests to access data that does not exist render the cache layer useless. In this case, all requests flow to the database layer, causing it to be overloaded.
Solutions: Consider the following options:
- Solution 1: Use a bloom filter to store cached keys. When access requests arrive, filter out non-existing keys to prevent these requests from reaching the database layer.
- Solution 2: If no data is found in the database, save empty objects with short expiration times to the cache layer.
- Solution 3: Verify the validity of request parameters based on specific business scenarios to prevent illegal requests from overloading the database.
2.2) Cache Breakdown
Symptoms: When a key fails, a large number of requests are sent to the database layer, causing the storage layer to crash.
Cause: To ensure the timeliness of the cached data, an expiration time must be set. However, if hotspot keys expire during a period of highly concurrent access, a large number of requests will be directly sent to the database through the cache layer. This increases the pressure on the database and may cause it to crash.
Solutions: Consider the following options:
- Solution 1: Use a mutex to ensure that, when cached data is invalidated, one request may access the database and update the cache while other threads wait and try again.
- Solution 2: Adjust the configuration so that cached data never expires. If no expiration time is set for the cached data, hotspot key expiration will not cause a large number of requests to flood the database. However, this makes the cached data “static”. Therefore, when the cached data is about to expire, update it in advance in an asynchronous thread.
2.3) Cache Avalanche
Symptoms: Multiple keys fail, and therefore a large number of requests reach the database layer, causing it to overload or even crash.
Cause: A cache avalanche occurs when the same expiration time is set for all cached data. As a result, the cache data is invalidated at a certain time and all requests are forwarded to the database. This crashes the database due to an instantaneous spike in traffic.
Solutions: Consider the following options:
- Solution 1: Use a mutex to ensure that only a single thread sends a request to the database.
- Solution 2: When multiple keys expire at the same time, add a random value of 1 to 5 minutes to the expiration time. This reduces the probability that a large number of keys expire at the same time. In addition, try to evenly distribute the expiration time of different keys as far as possible.
2.4) Summary
The terms, cache penetration, cache breakdown, and cache avalanche, are often mixed up and used interchangeably. They are all typical problems that occur when the system reads data from the cache. Cache penetration refers to attempts to obtain cached data that actually does not exist. In this case, requests always go through the cache layer and reach the storage layer. This vulnerability might be exploited by cyberattacks. The basic solution to this issue is to filter out illegal business requests. This situation has nothing to do with hotspot data and cache expiration times.
On the other hand, cache breakdown is a situation where the invalidation of hotspot keys causes a large number of requests to go directly to the database layer within a short period of time. The basic solution to this issue is to avoid concurrent operations on the database. Lastly, cache avalanche is a situation where the collective expiration of multiple keys causes database problems. In this case, the keys involved do not necessarily have to be hotspot keys. The basic solution to this issue is to distribute expiration times in a more evenly manner to prevent collective expiration.
3) Analysis — Data Update Scenarios
After a cache is introduced, data is stored in both the cache and the database. Therefore, when the data is updated, both storage locations must be updated, and different update sequences produce different results. The industry has already developed multiple methods to deal with data updates and the same is explained in the following sections.
3.1) Cache Aside Pattern
This is a common data update policy. The main process is as follows:
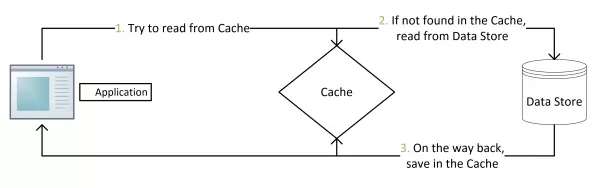
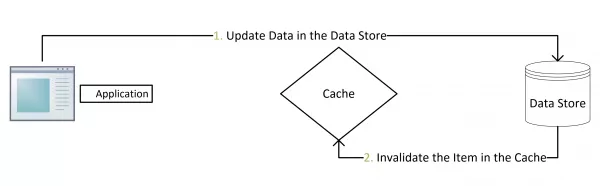
This method is characterized by the following processes:
- Invalidation: The application attempts to obtain data from the cache first. If the data is not found in the cache, the application obtains data from the database and stores the data in the cache after reading it successfully.
- Hit: The application reads data from the cache and returns the result.
- Update: Data is stored in the database, and then the corresponding data in the cache is invalidated.
When data is updated, the cache aside pattern first updates the database and then invalidates the cache. This is a good approach for cases that assume that both the database and cache update transactions are successful, it avoids the inconsistency caused by other update methods. This inconsistency issue will be further discussed in the following sections.
1) Why Do We Invalidate (Delete) the Cached Data Instead of Updating It?
1) Concurrent writes often cause overwriting and produce dirty data: When data is updated, use either of the two methods to process the cached data: update the cached data, or invalidate the cached data so that the next read request obtains the updated data from the database. In case of updating the cached data, multi-thread concurrent writes produce dirty data, as shown in the following figure.
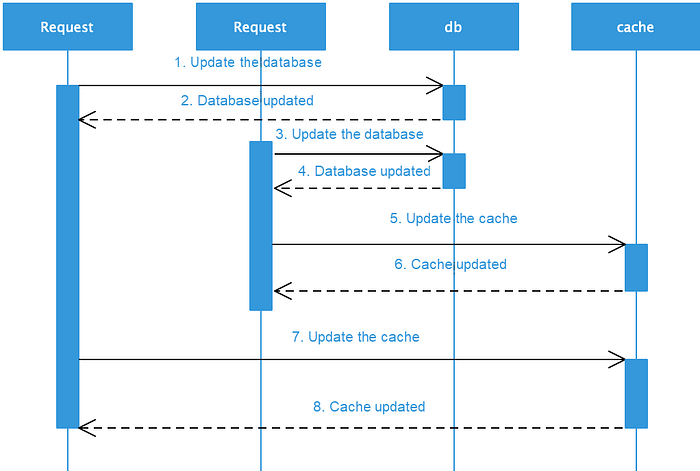
As shown in the preceding figure, assume that there are two threads, A and B. A updates the database first, then B updates the database and then the cache. However, since B updates the cache successfully and then A updates the cache successfully, the database stores the latest data but the cache stores the outdated dirty data. If the cache data is invalidated, the next read request is sent back to the database and loads the latest data to the cache, avoiding dirty data problems. Therefore, it is better to invalidate the cache in the case of a data update. For more information, see “Why does Facebook use delete to remove the key-value pair in Memcached instead of updating the Memcached during write request to the backend?”.
2) Data inconsistencies may occur while double-writing to different data sources: When data is written to the database and cache at the same time, the failure of either update operation may result in data inconsistency. Data inconsistencies due to physical failures are described in the next section. In addition, when the transaction is successful, regardless of whether one updates the cache or database first, these methods are prone to double-write failure in the case of concurrency. The operation sequence is shown in the following figure, which shows why this method is not recommended.
3) Update the cache before updating the database.

4) Update the database before updating the cache.
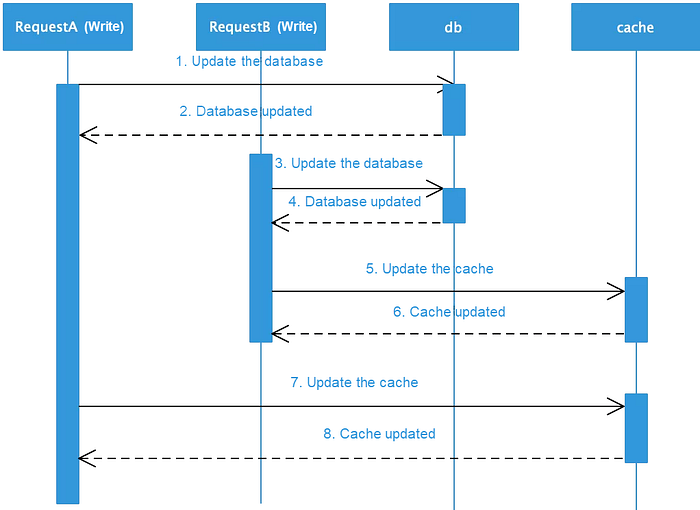
5) Use lazy data loading to avoid unnecessary computing consumption: If some cache values are obtained through complex computing and the cache is updated every time data is updated, computing performance is greatly wasted if this data is not actually read from the cache within a certain period of time. As a solution, it is completely feasible to recalculate the data for subsequent read requests. This approach is better suited to lazy data loading and will reduce the computing overhead.
2) What are Some Possible Update Sequences?
After determining that the cache will be invalidated after the data is updated, let’s take a look at several possible databases and cache update sequences.
1) Invalidate the cache before updating the database.
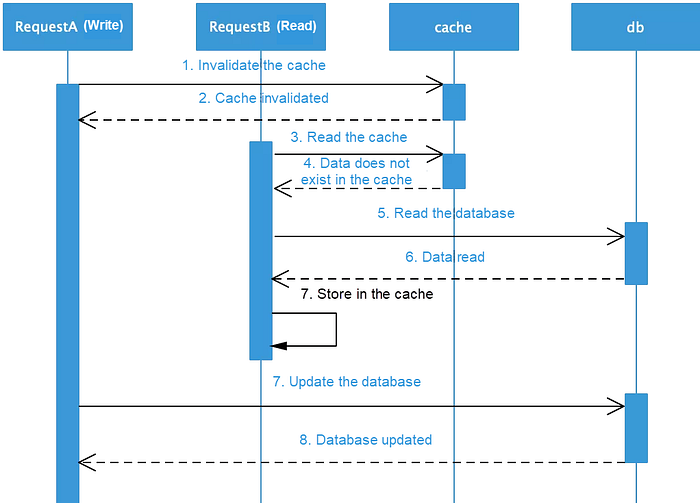
2) Assuming that operations are performed concurrently, it’s crucial to ascertain problems caused by sequence. As shown in the sequence diagram, when thread A first invalidates the cached data, and thread B’s read request discovers that the data is not in the cache, it reads the old data from the database and stores it into the cache again. As a result, all subsequent read requests read the dirty data in the cache. In this case, a delayed double-deletion policy must be used to effectively avoid this problem. The pseudocode is as follows.
cache.delKey(key);
db.update(data);
Thread.sleep(xxx);
cache.delKey(key);In this scenario, when a write request updates the database, the system waits for a period of time before deleting any dirty data that may have been cached by read requests. In addition, if the database adopts a primary-secondary separation architecture, read requests may read dirty data if the primary instance has not yet completed synchronization. This delayed double-deletion method requires thread hibernation, which reduces system throughput and is not an elegant solution. Alternatively, the asynchronous deletion may also be used. Of course, an expiration time must be set. When the cache expires, the latest data is loaded. In this case, the system must be able to tolerate data inconsistency for a period of time.
3) Update the database first and then invalidate the cache. This is the recommended method for updating data, but it may also result in data inconsistency. Consider the following sequence diagram.
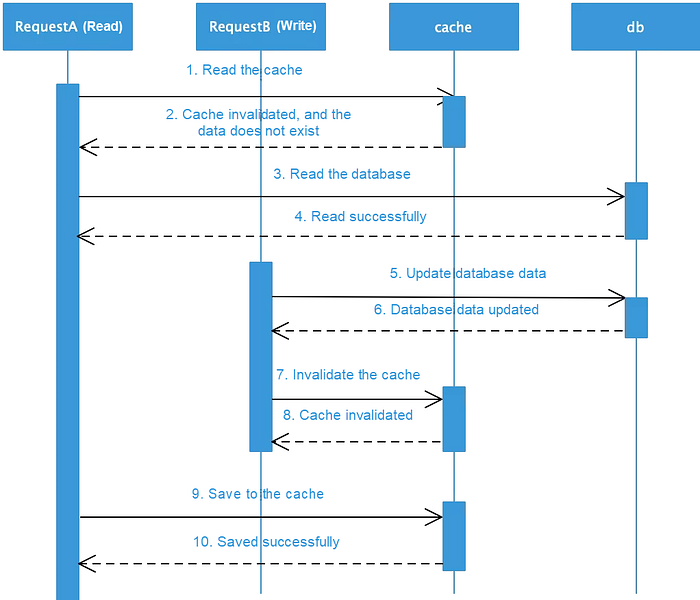
4) Assume that the cache just expired and the read request reads data from the database. After the write request updates the data, the cache becomes invalid, but the read request caches the old data again. Therefore, this method may also cause dirty data problems. In fact, the probability of this situation is very low. It only occurs when the database write is completed before the database read. Generally, database reads take less time than writes, so the likelihood of this situation is low. To avoid data inconsistency caused by “logical failures”, use the aforementioned asynchronous double-deletion policy and the expiration and invalidation method.
In the case of concurrent operations, both update sequences may produce dirty data in certain conditions. However, updating the database before invaliding the cache is the best way to ensure data consistency. Therefore, this method is recommended in the industry. This policy is also recommended in Facebook’s publication, “Scaling Memcache at Facebook”. When data changes occur, it’s critical to consider where the latest data is stored. Obviously, the cache aside pattern chooses to store the latest data in the database. Since data inconsistencies are likely, select a trusted device to store the latest data based on the specific business scenario.
3.2 Write/Read Through
While using the cache aside pattern, the caller controls the database and cache update logic. Obviously, this is a complicated process. With write/read through, from the perspective of the caller, the cache is the only data store for interaction, and the caller does not concern about the database behind the cache. In this solution, database updates are managed by the cache in a unified manner. The caller only needs to interact with the cache, and the entire process is transparent.
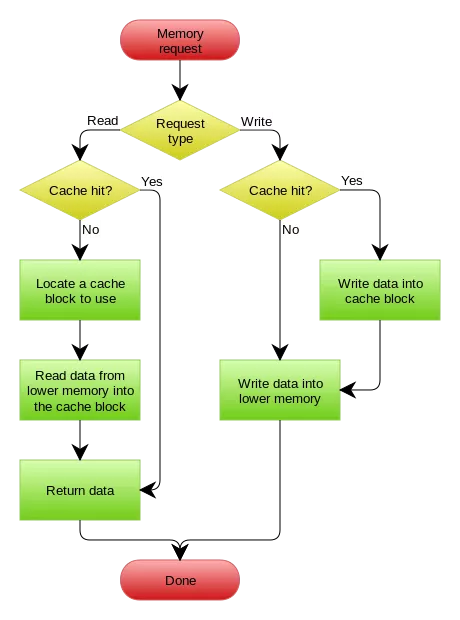
- Read Through: When data is updated, the cache is updated when queried, and the database is updated synchronously by the cache layer. In this case, the caller only needs to interact with the cache layer.
- Write Through: The Write Through process is similar to read through except that it occurs when data is updated. When data is updated, if no cache hit occurs, the database is directly updated and the new data is returned. If the cache is hit, the cache is updated, and then the database is updated synchronously by the cache itself. This is shown in the following figure:
3.3 Write Behind Cache Pattern
This method directly updates the cached data when data is updated, and then creates asynchronous tasks to update the database. This asynchronous method, quickly responds to requests and significantly increases system throughput. However, since the database is updated asynchronously, data consistency is weak. Any database update failure inevitably produces dirty data in the system. Therefore, it’s imperative to carefully design the system retry policy. In addition, if the asynchronous service crashes, consider how the updated data is persisted so that the service is quickly restored after the restart. While updating the database, trace the time sequence of each data update because concurrent write tasks may produce dirty data. Considering several details while using this method is a pre-requisite and therefore it is not easy to design a sound solution.
3.4 Thoughts on Update Policies
The aforementioned four update policies are widely used and their adoption across large-scale businesses in the industry offers valuable learnings. A careful analysis of these four update policies will teach a lot. Focus on the following aspects while designing update policies.
Where to Store the Latest Data?
A cache is used to improve system performance and system throughput by providing high-speed memory I/O reading. In addition, the presence of the cache prevents some read requests from reaching the database layer. This mitigates the pressure on the database, which is the area that most often creates a bottleneck. These are two important reasons why a cache is used. However, the problem is that data is stored both in a cache and a database. While updating data, consider how to store correct data in the most reliable storage medium and pick the appropriate data storage medium out of the two options based on their roles in the business.
The cache aside pattern updates the database and then invalidates the cache. This ensures that the latest and most correct data is always stored in the database and that the core business data is always reliable in the database. However, the problem is that the business logic is more complex and the system takes longer to process the update logic. If less important data is updated, use the write-behind cache pattern for cases that only need to update the cache to get a quick response. The disadvantage of this approach is that it often causes data inconsistency, and the data in the database is not necessarily the most reliable one. Therefore, different update policies represent a trade-off between storing the latest data in the most suitable place and improving system performance. Consider the specific business scenario characteristics while making this trade-off.
4) Data Inconsistency
4.1 Causes of Data Inconsistency
With the introduction of the cache, data is distributed across two different data sources. When data is updated, it is difficult to achieve data consistency in real-time unless a strong consistency solution is in place. However, this article doesn’t discuss this approach here. To find the most appropriate solution, analyze the following main causes of data inconsistency.
1) Data Inconsistency Due to Logical Failures: The previous section analyzes the four main data update policies. In the case of concurrent operations, regardless of whether the data is deleted from the cache before the database is updated or the database is updated before the cache is invalidated, data inconsistencies may occur. This is mainly because the operation sequence of asynchronous read/write requests causes data inconsistency. These cases are called “logic failures”. To solve the problems caused by concurrent sequences, the basic solution is to serialize asynchronous operations.
2) Data Inconsistency Due to Physical Failures: When the cache aside pattern is used, the database is updated before the cached data is deleted, and an asynchronous double-delete policy is used. In this case, if the cached data fails to be deleted, data inconsistency occurs between the database and the cache. However, database update and cache operations cannot be placed in one transaction. Generally, when a distributed cache is used, if the cache service is time-consuming, the database update and cache invalidation are placed in one transaction. However, this suspends a large number of database connections, dramatically compromising the system performance or even causing a system crash due to excessive database connections. Data inconsistencies caused by cache operation failures are called “physical failures”. In most cases, a retry method is used.
4.2 Data Consistency Solutions
Most business scenarios require eventual consistency. Common solutions to data inconsistency caused by physical failures include asynchronous cache deletion for message consumption and Binlog subscription. Common solutions for data inconsistency caused by logical failures include the synchronous queuing of asynchronous operations.
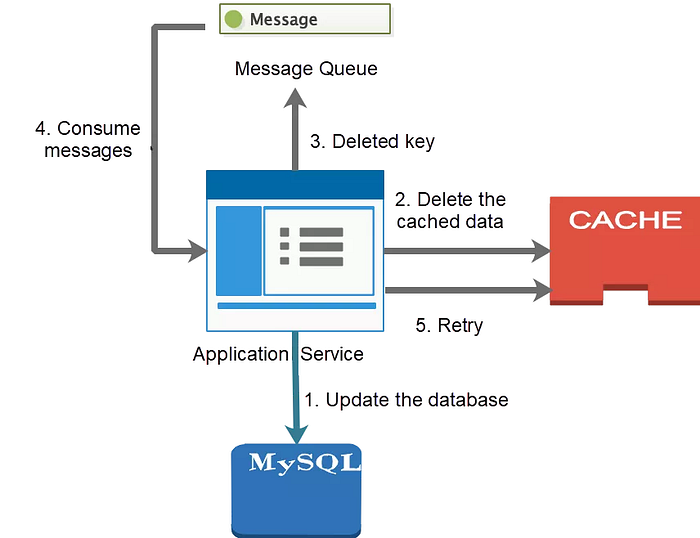
4.2.1 Asynchronous Cache Deletion for Message Consumption
This process is shown in the following figure:
4.2.2 Binlog Subscription
This process is shown in the following figure:
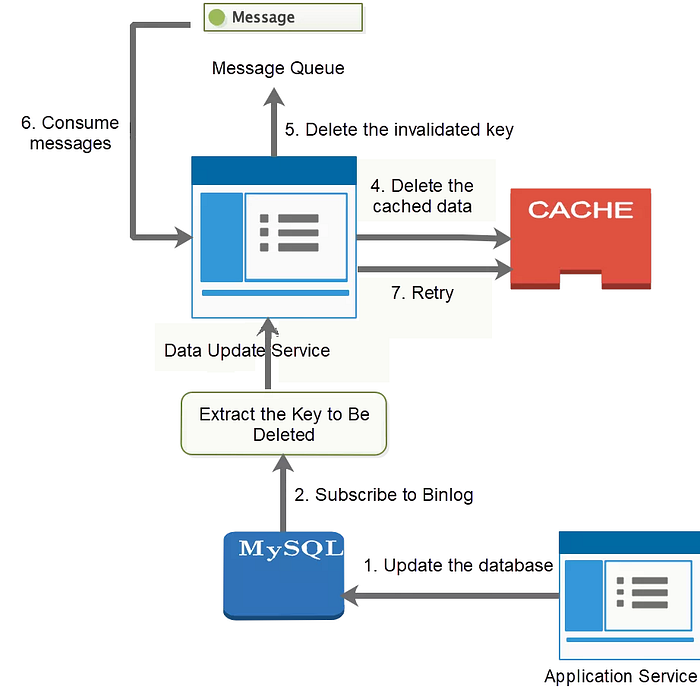
4.2.3 Queue Serialization
The analysis of the cache aside pattern shows that data inconsistency could result from concurrent operations, but this probability is low. In the case of concurrent reads and writes, data may be inconsistent if the cached data is deleted before the database is updated. Similarly, when data inconsistencies are caused by concurrent sequences, this is because a read request reads old data before the write request was completed. Cases that ensure read requests are processed after write requests by serializing request processing make sure that read requests will always read the latest data updated by write requests.
A queue is the most common request serialization method. A queue may only correspond to one worker thread. Write requests for updating data are placed in the queue and wait for asynchronous processing. If a read request obtains data from the cache, the result is returned. If no target data exists in the cache, the read request is placed in the queue and must wait for the write requests to finish updating data.
However, make sure to consider the following issues while using this solution.
1) Read requests may be held up for a long time: If multiple write requests exist in the queue, the subsequent read requests must wait a significant amount of time for the write requests to be completed. To address this problem, set a timeout policy for read requests. Once the timeout period elapses, the data is read directly from the database and returned, which avoids long response times. In addition, perform a stress test across the business to check how many write requests are queued during peak hours. If too many write requests enter the queue, consider a queue optimization method and corresponding solutions.
2) Multiple queues distribute pressure: Multiple queues are created and executed concurrently through hash or other routing methods based on data items. This improves system throughput.
3) Complex operations require comprehensive consideration: As queues are used for serialization, it is necessary to consider queue availability, queue blocking, and robust disaster recovery policies in the case of service crashes. Generally, the overall solution requires a great deal of thought. This method helps to achieve strong data consistency, but it greatly reduces the throughput of the system and results in complex operations. Like any solution, it has both cons and pros. Therefore, weigh both of them when selecting an appropriate technical solution based on a specific business scenario. There are many solutions for strong data consistency, but they generally involve complex operation designs. In most business scenarios, achieving eventual consistency is enough.
In addition to the three common methods discussed previously, setting expiration times for the cache and performing regular full synchronization is the simplest and most effective way to approach eventual consistency.
5) Common Problems
Analyzing data update policies shows that it is not easy to use a cache correctly. Practically, there are many problematic scenarios to deal with, including the following:
1) Expired and Unexpired Cached Data: Analyze the specific scenario to determine whether to set an expiration time for cached data. For some long-tail products, when most data is often read and there is a large cache space available, consider adjusting the configuration to prevent data expiration. But does this turn the data into static data? When the cache space becomes full, the data is removed from the cache based on the elimination policy. In addition, when the data is updated, use Binlog or other methods to asynchronously invalidate the cache data. If the costs of asynchronous message update operations are too high or the external system cannot subscribe to asynchronous Binlog updates, it is necessary to use cached data expiration to ensure the eventual consistency of the data.
2) Multidimensional Caching and Incremental Updates: If an entity contains multiple attributes, when the entity changes, all the attributes must be updated, which incurs a high cost. However, only a few attributes are actually changed. Therefore, split up the attributes of an entity into different dimensions and cache the attributes based on these dimensions. Thus, just update the corresponding dimensions while updating the attributes.
3) Large Values: To address the large value problems, consider compressing values, dismantling them during caching, and then aggregating data in business services.
4) Hotspot Data Caching Problem: Obtaining hotspot data from the remote cache by each request overloads the cache system and slows down the response to requests for cached data. To address this problem, use a cache cluster and mount more secondary caches to ensure that data is read from secondary caches. For hotspot data, use an application’s local cache to reduce the request load on the remote cache.
5) Data Push: Load data to the cache in advance so that a large number of requests are not sourced back to the database when the cache is empty. If the capacity of the cache is large, consider fully preloading data to the cache. If capacity sufficiency is a priority, preload only frequently accessed hotspot data. Meanwhile, lookout for batch operations and performance problems caused by slow SQL statements. Therefore, a reliable monitoring mechanism is required throughout the data push process.
6) Unexpected Hotspot Data: When additional hotspot data that is not predicated by the business occurs, a hotspot discovery system is required to collect hotspot keys and monitor unexpected hotspot data in real-time. Push these keys to the local cache to prevent the remote cache service from crashing due to the failure to correctly predict hotspot keys.
7) Fast Recovery of Cache Instance Faults: When a cache instance fails and the cache is stored on sharded instances if the cache key routing policy adopts the modulo mechanism, the traffic of the faulty instance will quickly reach the database layer. In this case, a primary-secondary mechanism must be adopted so that other instances take over for the failed instance. However, this method will cause the cache hit ratio to decrease rapidly when the horizontal scaling capacity is insufficient and a node is added to the sharded instances. If consistent hashing is used for the key routing policy and an instance node fails, some cache misses on the hashing ring will not reach the database. However, for hotspot data, high node loads may become a system bottleneck. The following methods are used to correct instance faults:
- Use a primary-secondary mechanism to back up and ensure the availability of data.
- Downgrade the service by adding cache instances and then pushing data in asynchronous threads.
- Adopt a consistent hash routing policy. When the hotspot data reaches a certain threshold, downgrade to a modulo policy.
6) Factors Affecting Cache Performance
There are many factors that affect the overall performance of the cache to a greater or lesser extent, such as the impact of the language characteristics. For example, the impact of GC needs to be considered in Java. There are multiple factors to consider when trying to increase the cache hit ratio. The most important factors are as follows:
1) Factors Impacting the Cache Hit Ratio: Consider the following factors that impact the cache hit ratio.
- Business Timeliness Requirements: A cache is suitable for business scenarios with more reads than writes. The nature of the business determines its timeliness requirements, and different timeliness requirements determine which cache update policies and expiration time settings are the most suitable. Businesses with low timeliness requirements are more suitable for using the cache and allow achieving a higher hit rate.
- Cache Granularity Design: Generally, scenarios with smaller cache object granularities are better suited for using the cache. Such scenarios do not involve frequent updates that decrease the cache hit ratio.
- Cache Elimination Policies: If cache space is limited, different cache elimination policies also affect the cache hit ratio. If the eliminated cache data is frequently requested in the future, the cache hit ratio will definitely fall.
- Cache Deployment Methods: When using a distributed cache, perform capacity planning and implement disaster recovery policies to prevent large-scale cache failures caused by cache instance failures.
- Key Routing Policies: Different routing policies produce different effects when a node instance fails. For example, the cache hit ratio will fall if the modulo method is used for horizontal scaling. Note that no universal method applies to improve the cache hit ratio. As a rule of thumb, implement caching for frequently accessed business data with low timeliness requirements.
2) Serialization Methods: Using a remote cache service inevitably requires data transmission over the network after serialization. So, selecting different serialization methods will affect cache performance. When selecting a serialization method, consider the time consumed by serialization, the size of the transmitted packets after serialization, and the computing overhead produced by serialization.
3) GC Impact: While adopting a multi-level cache or using the application’s local cache for large values, consider the GC impact of large objects for Java applications.
4) Cache Protocol: Understand the pros and cons of different cache protocols, such as Redis and Memcached, and select the protocol that best suits your business scenario.
5) Cache Connection pool: To improve access performance, you need to properly configure the cache connection pool.
6) Sound Monitoring Platform: Consider whether a cache monitoring platform can be used to track cache usage, the overall performance of the cache service, and discovery policies for unexpected hotspot data. In this way, the availability and performance of the cache service can be comprehensively guaranteed.
7) Multi-level Cache Design Case
When users send requests to the underlying database, the requests go through many nodes. Therefore, caches are placed at different levels throughout the process. Obviously, by placing a cache at the point nearest to users, improve system responsiveness. A multi-level cache have an even more significant effect by increasing system throughput and greatly reducing the backend load. Add caches throughout the entire process as follows:
Request Initiation > Browser/Client Cache > Edge Cache/CDN > Reverse Proxy (Nginx) Cache > Remote Cache > In-process Cache > Ddatabase Cache
The general technical solution for a server-side multi-level cache is as follows.
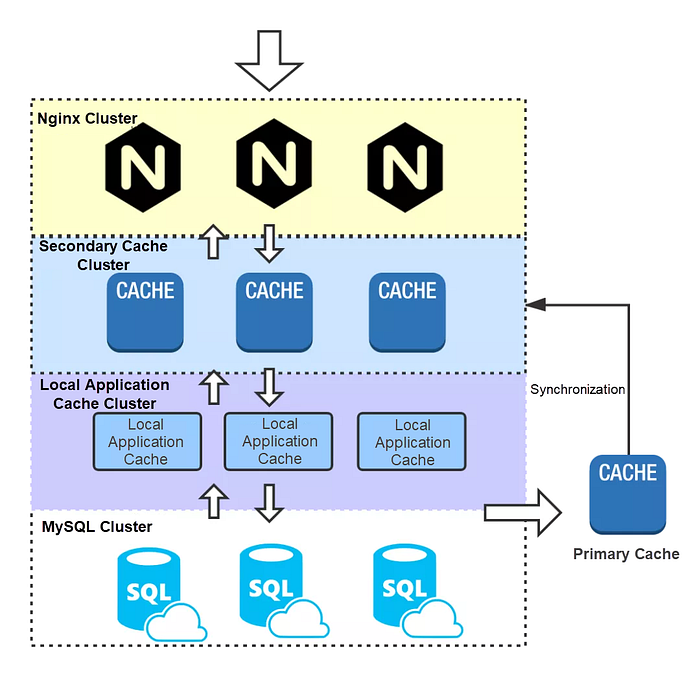
The main process is as follows:
1) The request first reaches Nginx, reads the local Nginx cache, and then returns the cached data if it hits the cache. In this example, the load balancing routing policy adopts the polling method, which distributes access pressure in a more evenly manner. The consistent hashing method improves the cache hit ratio, but it also imposes excessive pressure at a single point. When the consistent hashing policy is used, it switches to the polling mode when the traffic reaches a certain threshold.
2) If the Nginx cache is not hit, the distributed cache is read. To ensure high availability and improve system throughput, the remote distributed cache generally uses a primary-secondary structure. In this example, data is read from the secondary cache service cluster and the request returns the data if it hits the cache.
3) If the request does not hit the cache, it reads the local application cache (in-heap or out-of-heap cache). This cache also adopts a polling or consistent hashing routing policy. If the cache is hit, the data is returned and written back to the Nginx cache. To avoid database crashes resulting from excessive traffic due to problems with the secondary cache service, try to read the primary cache service in this case.
4) If the request does not hit any caches, the database is queried, the obtained data is returned, and the data is asynchronously written back to the primary cache and the local cache of the application. The primary cache synchronizes the data to the secondary cache cluster through the primary-secondary synchronization mechanism. When multiple application instances asynchronously write data to the primary cache, consider the potential data disorder problem.
In addition, for some unexpected hotspot data, such as in case of Weibo, when a celebrity gets married, the access traffic instantly impacts the backend. In the multi-level cache design presented previously, introduce a hotspot discovery system to discover unexpected hotspot data. Specifically, use Flume to subscribe to Nginx logs, consume messages, and collect hotspot data through real-time computing frameworks such as Storm. When the monitoring system detects hotspot data, the data is pushed to each cache node. The overall cache design is as follows:
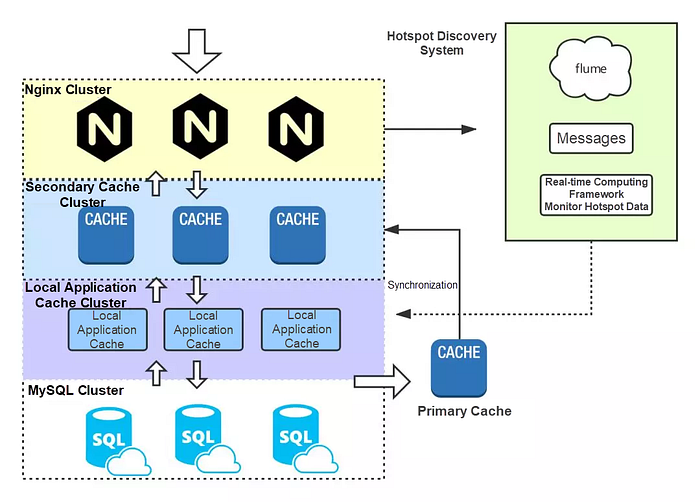
8) Summary
In the pursuit of high performance, a cache is the first thing that every developer tries. They think of a cache as a good antidote to system performance bottlenecks. This article provides a systematic summary and analysis of caches to show that the improper use of caches may turn this antidote into a poison that inhibits us from achieving an optimal solution. If you rush to use a cache, you will often ignore things that you need to consider. In this case, system maintenance costs will rise and the system will become more complex. However, we don’t recommend refraining from using a cache. In fact, in the case of high concurrency, obtaining data through a high-speed I/O cache enables a quick response to each request, greatly improving system throughput and supporting a higher number of concurrent users. The extensive use of caches in existing high-concurrency and high-traffic Internet applications proves that caching is an effective solution to optimize overall system performance.
Not every developer has the opportunity and challenge of dealing with high-concurrency Internet architectures and high access traffic and application scales. However, this does not mean that studying these general technical solutions in depth is unnecessary. When using a single cache, you will find that data inconsistency caused by highly concurrent reads and writes will plague many concurrent scenarios. The cache works normally if only one thread exists. However, many unexpected problems will occur in the case of concurrent operations. The present analysis explains the main causes of these problems and may allow developers to gradually develop their own methodologies. Studying each technical component in a systematic way, helps to see that the solutions widely adopted in the industry have gradually evolved from historical experience.
The ultimate aim of technology is to increase business value, while business growth helps drive technological innovation. To design a set of reasonable technical solutions that are suitable for business applications, hard and intensive work is required. It is hard to understand the limitations of each technical solution and choose the technical solutions most appropriate to specific businesses. The optimal solution is simply the solution that delivers the greatest value through the combination of business and technology. Every solution has its own pros and cons, and therefore we need to know how to make appropriate trade-offs. If you understand the technology but not the business, you will not be able to fully utilize your capabilities. At different stages of our careers, we divided our limited energy differently between technology and business. Our focuses differ at different times. Just as in life, we must look to find the best solution for our current situation. To find this optimal solution, we must rely on our own informed intuition.
References
- Dive into distributed cache systems
1) https://book.douban.com/subject/27602483/?spm=ata.13261165.0.0.1fbe62a58KTCCF
- Discussions of cache penetration, cache breakdown, and cache avalanche:
1) https://www.cnblogs.com/Leo_wl/p/9062029.html?spm=ata.13261165.0.0.1fbe62a58KTCCF
2) https://blog.csdn.net/zeb_perfect/article/details/54135506?spm=ata.13261165.0.0.1fbe62a58KTCCF
3) https://www.cnblogs.com/Leo_wl/p/9062029.html?spm=ata.13261165.0.0.1fbe62a58KTCCF#_label0_0
- Cache update policies:
1) https://www.jianshu.com/p/8950c52ce53b?spm=ata.13261165.0.0.3d1462a5BuyJzs
2) https://www.jianshu.com/p/22c7e9ab5d15?spm=ata.13261165.0.0.3d1462a5BuyJzs
3) https://www.cnblogs.com/rjzheng/p/9041659.html?spm=ata.13261165.0.0.3d1462a5BuyJzs
4) https://www.jianshu.com/p/8950c52ce53b?spm=ata.13261165.0.0.3d1462a5BuyJzs
- Eventual consistency:
1) https://blog.kido.site/2018/11/24/db-and-cache-preface/?spm=ata.13261165.0.0.3d1462a5BuyJzs
2) https://msd.misuland.com/pd/3255817997595443436?spm=ata.13261165.0.0.3d1462a5BuyJzs
3) https://blog.51cto.com/14214194/2411931?spm=ata.13261165.0.0.3d1462a5BuyJzs
4) https://www.cnblogs.com/pomer-huang/p/8998623.html?spm=ata.13261165.0.0.3d1462a5BuyJzs
- Cache design:
1) https://blog.csdn.net/zjttlance/article/details/80234341?spm=ata.13261165.0.0.3d1462a5BuyJzs
2) https://stor.51cto.com/art/201908/600603.htm?spm=ata.13261165.0.0.3d1462a5BuyJzs
3) https://yq.aliyun.com/articles/652472?spm=ata.13261165.0.0.3d1462a5BuyJzs&utm_content=m_1000018600
4) https://blog.csdn.net/ruanchengmin/article/details/79210632?spm=ata.13261165.0.0.3d1462a5BuyJzs
- Cache replacement policies:
