Voiceprint Recognition System — Not Just a Powerful Authentication Tool

Introduction
In this advanced age, when mobile Internet is the norm, people leverage social networking, online shopping and online financial transactions without the need of being physically present at places. As a result, identity authentication has become the most critical security activity in the online world. The traditional solution uses a password or a private key that you need to remember. In fact, many people prefer keeping simple passwords such as “123456” to shuttle through the Internet world. Unfortunately, this makes their online data an easy target for hackers. Traditional solutions are a risky affair as the passwords are forgotten or lost and are also prone to hacker attacks.
Are you still using the default password “admin” for your home router?
Do you know that easy-to-crack passwords are the most vulnerable link in the security realm of the Internet of Things (IoT)?
Solutions
Fortunately, we all have unique “living passwords” on our bodies, such as the fingerprints, face, voice, and eyes. They are the unique and distinctive characteristics of individuals popularly called “biometric signatures.” Voice is just one way of reflecting a person’s identity. In reference to the nomenclature for “fingerprint,” we also call it “voiceprint.”
As per the United States National Biosignature Test Center at San Jose University, “Fundamentals of Biometric Technology,” below is a quick comparison of types of biometrics signatures based on various factors:

Comparison Between Various Biometric Signatures
Let’s read about the voiceprint recognition system and its underlying principle.
About Voiceprint Recognition System
Voiceprint refers to the acoustic frequency spectrum that carries the speech information in a human voice. Like fingerprints, it has unique biometric signatures, is individual-specific, and can function as an identification method. The acoustical signal is a unidimensional continuous signal. On discretization, you will get the acoustical signal that can be processed by conventional computers.

Discretized Acoustical Signals Processed by Computers
Similar to the widely-used fingerprint technology on mobile phones, voiceprint recognition (also known as speaker recognition) technology is also a bio-identification technology that extracts phonetic features from the speaker’s voice signals to validate the speaker’s identity. Everybody has a unique voiceprint gradually formed throughout the development process of our vocal organs. No matter how remarkably similar the imitated voice can be to the original voice, their voiceprints will remain different.
The Chinese saying of “someone may not yet be here bodily, but you can already hear him/her speaking” in real life vividly describes a scene where you identify another person by the voice. This explains why your mother knows it’s you before you even finish saying “hello” over the phone. This is an extraordinary ability humans have acquired through long-term evolution. With the latest technological innovations, recognition systems can quickly identify a person after listening to 8 to 10 words; it is still not feasible to identify voice with a single word. It can also distinguish if you are one of the specified 1,000 people after speaking for more than a minute. It relies on an important concept applicable to most of the biometric identification systems: 1:1 and 1: N. It also encompasses a unique concept unique for the voiceprint recognition technology: text-dependence and text-independence.
Let’s learn about its principles in detail in the proceeding section.
Working Principle
1:1 Recognition System
The working model of this biometric identification system requires you to provide your identity (account) and biometric features beforehand and saves it as a template. During processing, the system compares the entered features with the stored biometric characteristics, to determine whether the two sets match. Such systems are popularly known as 1:1 recognition system (also called speaker verification).
1: N Recognition System
The working model of this biometric identification system doesn’t ask for biometric features before processing. It only requires the biometric features during runtime and then compares it with all the multiple records of biometric features stored in the background to determine the right match. Such systems are popularly known as 1: N recognition system (also called speaker identification).
Figure 1 below shows a quick comparison between both the recognition systems.
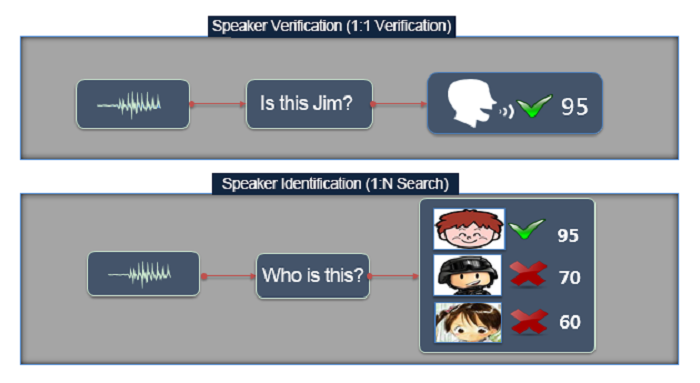
Figure 1: Speaker Verification and Speaker Identification
Figure 2 below shows the working process of a simple voiceprint recognition system:
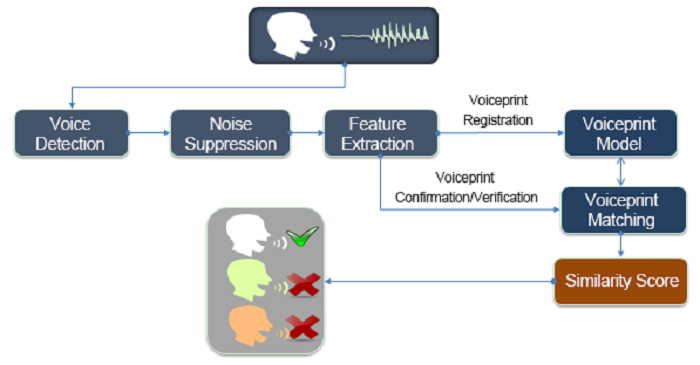
Figure 2: Working Process of a Voiceprint Recognition System
From the perspective of users’ speech content, there are two types of voiceprint recognition systems, namely text-dependence and text-independence.
As their names imply, “text-dependence” refers to a system that requires the user to only say system-prompted content or content within a small allowed range, while “text-independence” does not restrict the content spoken by the user. This way, text dependence content only requires the recognition system to process the small-range acoustic differences between users. Since the content is similar, the system only needs to care about the voice differences, with relatively less difficulty. Text independence systems require a recognition system not only to consider the distinct differences between the user voices but also to process the speech differences caused by different content, with relatively higher difficulty.
At present, there is a new technology that falls between the two, popularly known as “limited text-dependence.” These systems collocate some numbers or symbols at random and require users to read the corresponding content to get the voiceprint recognized. Due to this randomness, the collected voiceprints vary in content sequence every time. This feature aligns with the widely-used short random numbers (such as digital verification codes). It is useful for identity validation or, in combination with other biometric signatures such as the face, to form multiple-factor authentication systems.
Voiceprint Recognition Algorithm: the Technical Details
Let’s delve a little deeper into the technical details of the voiceprint recognition algorithm. In the feature layer, the classic Mel-Frequency Cepstral Coefficients (MFCC), the Perceptual Linear Prediction (PLP), the Deep Feature, and the Power-Normalized Cepstral Coefficients (PNCC) are all outstanding acoustic features used as inputs for model learning. However, MFCC remains the most frequently used feature.
It also allows you to use multiple features by combining any of the feature or model layers. In the machine learning model layer, the iVector framework that N.Dehak proposed in 2009 still takes a dominant role. Although the deep machine learning has been in the limelight today, and the voiceprint sector cannot escape its impact, the DNN-iVector derived from the legacy UBM-iVector framework only replaces the MFCC with the DNN (or BN) used for extracting features. Besides, it uses the DNN (or BN) as a supplement of MFCC, and the back-end learning framework remains iVector.
Figure 3 demonstrates a complete training and testing process of the voiceprint recognition system.
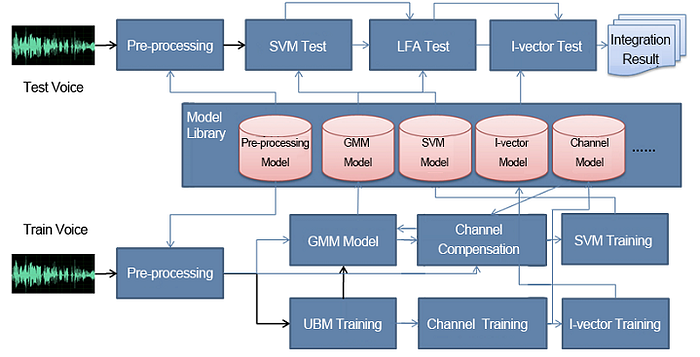
Figure 3: Complete Training and Recognition Framework of Voiceprint Recognition Algorithms
We can see that the iVector model training and the channel compensation model training that follows are the most relevant links. In the feature phase, you can use the BottleNeck feature to replace or supplement the MFCC feature and input it to the iVector framework for model training, as shown in Figure 4.
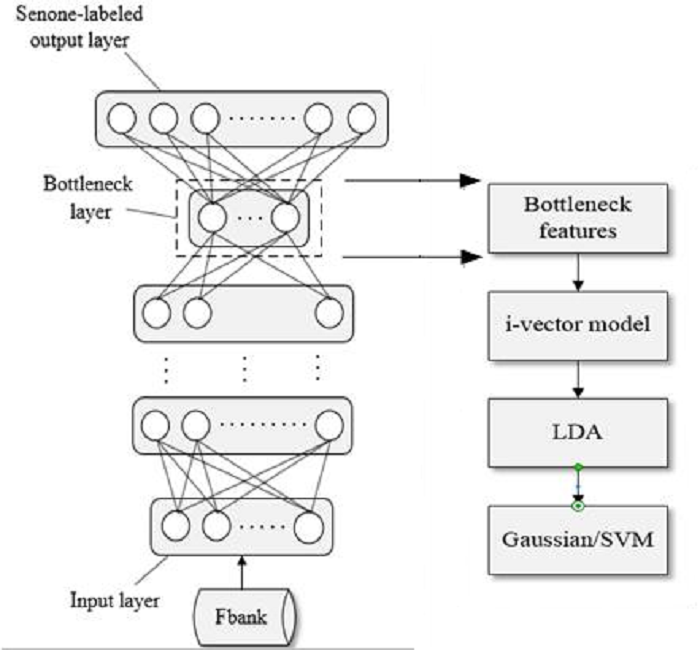
Figure 4: Training iVector Model with the BottleNeck Feature
In the system layer, different features and models can depict the speaker’s voice features from different dimensions. Coupled with effective score normalization, various subsystems can be integrated to elevate the overall system performance substantially.
Conclusion
In this blog, we dissected and learned the basics of the voice recognition system, the details about its underlying principles, and how it plays a significant role in biometric identification industry.
